为什么迁移 Go
我们问为什么迁移 Go 基本就是问迁移 Go 能给我们带来哪些好处,以及为什么迁移的是 Go 而不是 Java 甚至是 Typescript.
迁移 Go 能带来哪些好处
性能
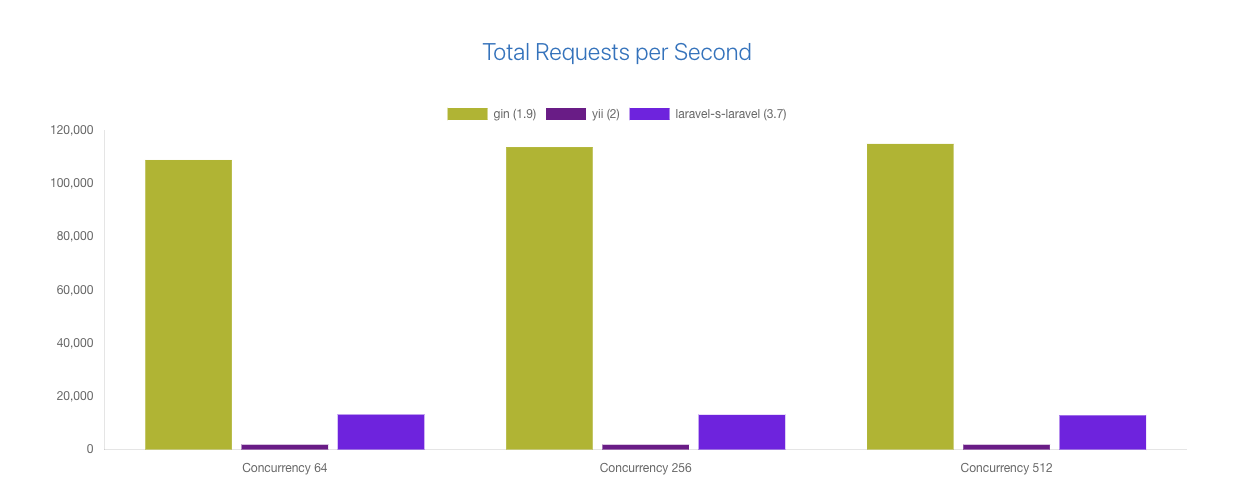
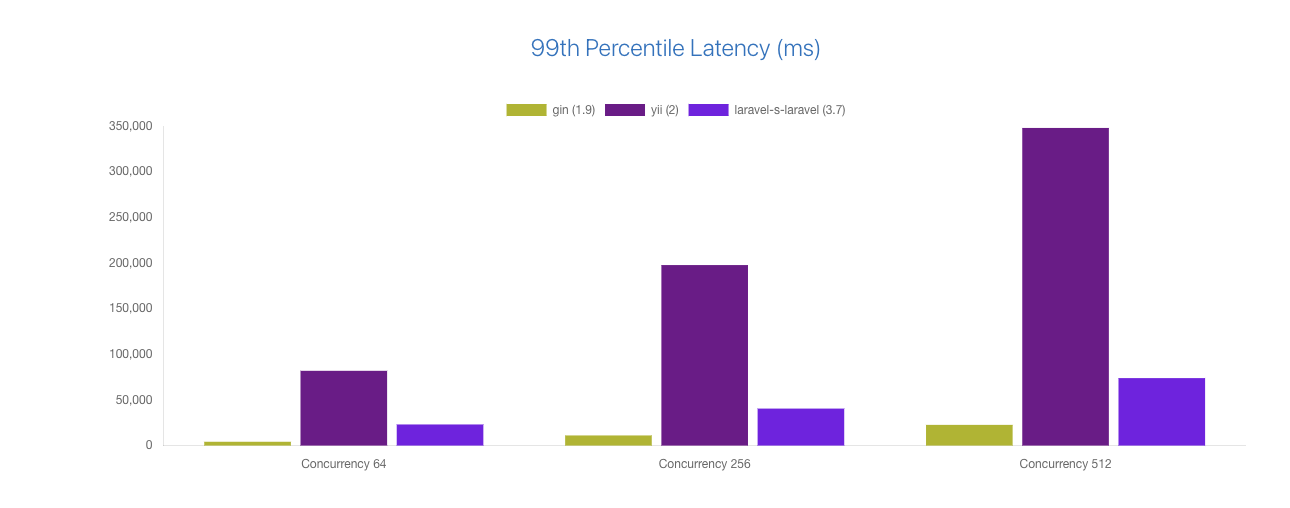
压测环境:
All frameworks are benchmarked using wrk (threads: 8, timeout: 8, duration: 15 seconds) with 64, 256, and 512 concurrency.
Hardware used for the benchmark:
- CPU: 8 Cores (AMD FX-8320E Eight-Core Processor)
- RAM: 16 GB
- OS: Linux
- 并发请求能力(go gin vs php laravel vs php yii)
- 请求延时(go gin vs php laravel vs php yii)
- 内存和 CPU 消耗

维护成本
- 强类型带来的类型安全优势
// 避免类型不匹配带来的隐式转换问题
$num = 1;
$str = "1";
var_dump $num == $str; // true
// 避免代码的理解成本以及误用的可能
public function getAPIData($params){ // params 到底是什么类型? params 中是哪些参数?
}
str = "123";
getAPIData(str); // 写代码时误传入了一个 string, 也很难发现
轻量化
package main
import (
"io"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request) {
io.WriteString(w, "Hello world!")
}
func main() {
http.HandleFunc("/", hello)
http.ListenAndServe(":8000", nil)
}
不需要 nginx 等 proxy server
为什么迁移的是 Go
Go 语言是从 2009 年 11 月由 google 推出的,从 2012 年左右开始兴起,Go 的兴起不仅仅是因为语言本身的一些优势(轻量化,高性能以及可扩展等),同时也是伴随微服务和云原生浪潮的,计算资源虚拟化和可编排的两个重要的基础框架 k8s 和 docker 就是 Go 语言写的。原本大量使用动态语言开发的公司因为受到动态语言性能和维护成本的限制,同时基于上云的需求开始向 Go 迁移,从而培养了国内大批的 Go 相关从业者。
除此以外,相比于 Java, Go 的学习成本非常低。Java 的 web 应用开发普遍基于 Spring 全家桶,除了 Java 框架本身的学习成本以外,Spring 框架本身也有很大的学习难度。而 Go 语言虽然也有很多框架和库,但是基于你所使用的场景你可以自主选择所需要的组件来屏蔽框架的复杂性。
迁移 Go 以后会有哪些痛点
- Go 不是一门 OOP 语言,这里没有继承模式
class CompareController extends L_Basic_Controller {
}
Go 使用组合替代继承模式
type Interface interface {
Method()
}
type A struct {
}
func (a A) Method() {
// implementation
}
type B struct {
A
}
var b B
b.Method() // calls A.Method
- Go 是强类型的
type Interface interface {
Method()
}
type A struct {
}
func (a A) Method() {
// implementation
}
type B struct {
A
}
func CallMethod(a A) {
a.Method()
}
func CallMethod1(i Interface) {
i.Method()
}
var b B
// 不可以
CallMethod(b)
var a A
// 可以
CallMethod1(a)
CallMethod1(b)
- Go 的泛型是阉割过的
- Go 没有很多语法糖,连遍历数组和字典的方法也要自己写
- Go 需要不停地做错误处理
Go 的部分基础结构
- 常量类型(bool, string, int, float等)
- int 类型包括 int, int8, int16, int32, int64, int 根据操作系统底层的位数确定是 int32 还是 int64. int 类型之前的转换通过显式声明。比如 int32(1), 高转低比如 int64 转 int32 可能会丢失信息
- string 类型是不可变的,比如 str[1] = xxxx. 通过 fmt.Sprintf 以及 string 拼接等方式都是产生了新的 string
- 数组和 slice
- 在 Go 语言中,数组是具有固定长度的,比如
var a [2]int, 而 slice 是可以动态进行扩容的var a []int, slice 底层就是一个指向数组的指针,一般我们不会用到数组,使用 slice 一定要先进行初始化。slice 的初始化方式有三种:make([]int, 0), 初始化一个 len为 0, cap 为 0 的 slice,里面没有元素。在使用时动态进行扩容make([]int, 0, 8)初始化一个 len为 0, cap 为 8 的 slice,里面没有元素。在需要容量小于 8 的时候不需要扩容make([]int, 8)初始化一个 len为 8, cap 为 8 的 slice, 里面有 8 个零元素。
- 在初始化的时候能确定需要的 cap 的时候,尽量提前使用
make([]int, 0, len(xx))的方式声明. 避免频繁扩容分配内存
- map
- 在 golang 中,map 是非并发安全的,这意味着多个 goroutine 对同一个 map 进行写的时候,会导致不可 recover 的 panic. 常见的并发不安全包括同时起多个 goroutine 对一个本地变量 map 进行修改以及声明了一个全局变量 map, 多个请求(每个请求其实都是一个 goroutine)都会对这个 map 进行修改。解决这个问题可以使用并发安全的
sync.Map或者使用sync.Mutex/sync.RWMutex. https://go.dev/play/p/rCoJ_Q4Mpvw
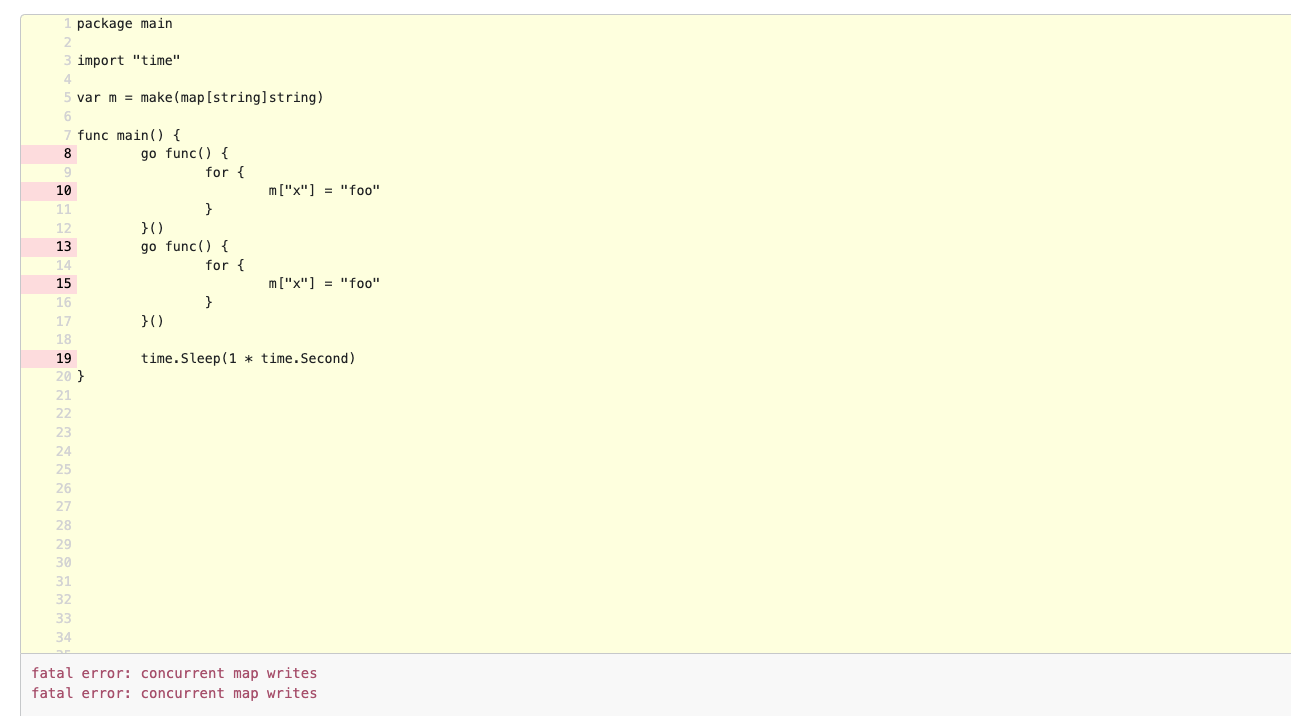
- 同时 golang 中的 map 是引用类型,这意味其他函数内对 map 的修改是对本函数可见的。https://go.dev/play/p/2Yd4JkUqIBe 同样是引用类型的还包括 slice, channel.
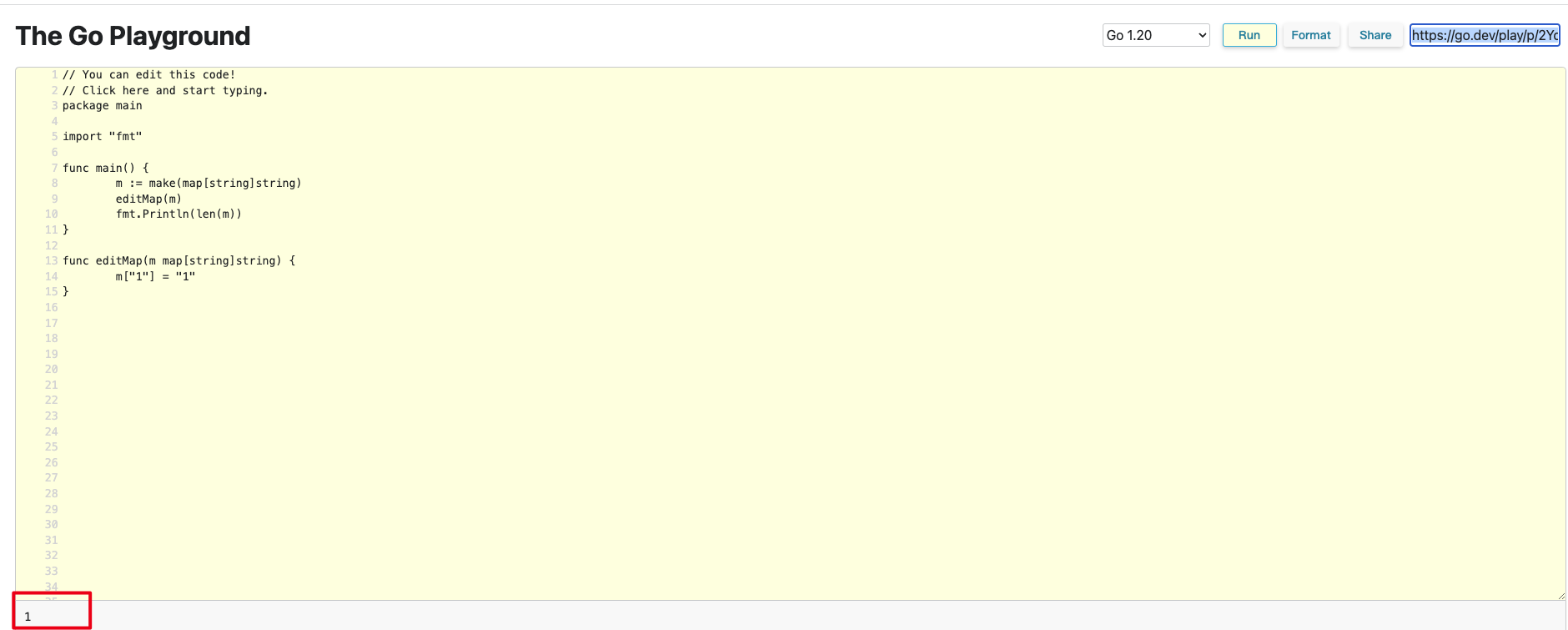
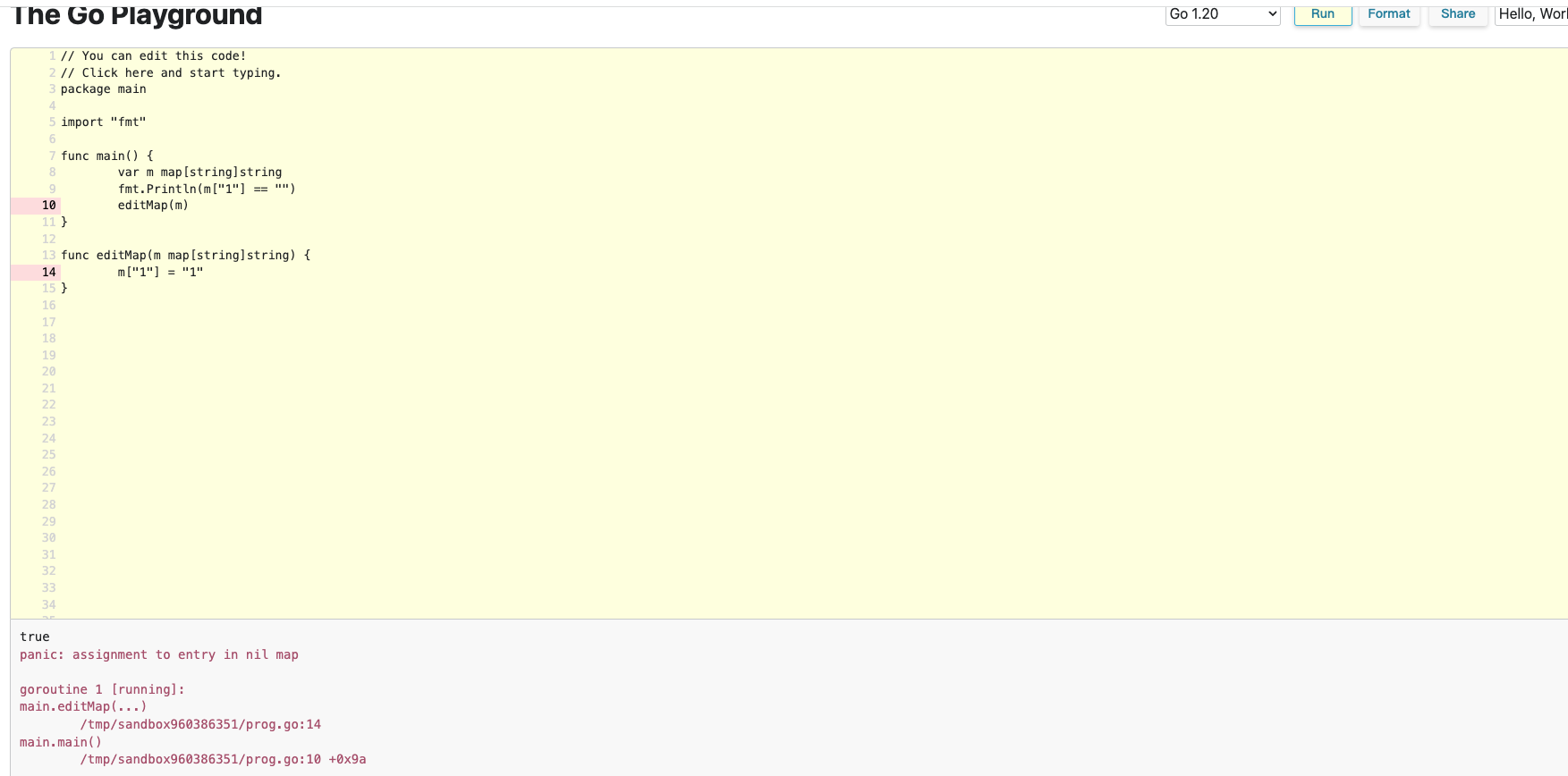
- 对 nil map 进行读会返回空值,而对 nil map 进行写则会 panic. 判断 map 是否存在元素通过 value, ok := m[key] 中的 ok 进行判断,这样避免 map 中是有存在相应元素,但是空值的情况. https://go.dev/play/p/WffE9tOCVxA
- func fact: golang map 的遍历顺序是不保证的,虽然 map 底层存储结构是有序的,但是 go 语言开发者为了避免使用者依赖 map 有序,故意在底层遍历时引入了遍历随机起点。
- channel
- golang 中的 channel 主要是用来信号同步以及数据传递的。信号同步一般用于两个 goroutine 之间协调执行顺序,优雅退出等 https://go.dev/play/p/LtyI9GqWNsF,同样可以实现这个功能的包括
sync.WaitGroup. 数据传递就类似生产者消费者模型,多个 goroutine 之间传递数据 https://go.dev/play/p/hMf2etQSFq1 。 - 未收到 channel 信号或者 channel 一直未关闭会导致 goroutine 一直阻塞,出现死锁或者内存泄漏。所以 channel 建议创建后一定 defer close(ch).
- 向已经关闭的 channel 发送数据会导致 panic. 所以一般关闭 channel 由生产者进行关闭。
- 一般我们不会用到非缓冲的 channel, 比如 ch := make(chan int, 1). 这种 channel 是非阻塞的,意味着缓冲区里没有数据或者没有发送数据的时候读取一直会是空值。比如 data, ok := <- ch。这时候 data 和 ok 分别是 0 和 false.
- goroutine
- golang 中的 goroutine 是一种协程的概念,也就是用户态线程。用户态线程和系统线程之间是 M:N 的映射关系,用户态线程之间的切换不会陷入操作系统调用,也就是不存在用户态和内核态之间的切换,所以更轻量。同时一个 goroutine 的开销基本在 kb -> mb 级别,这意味着内存开销很小,并发度更大。
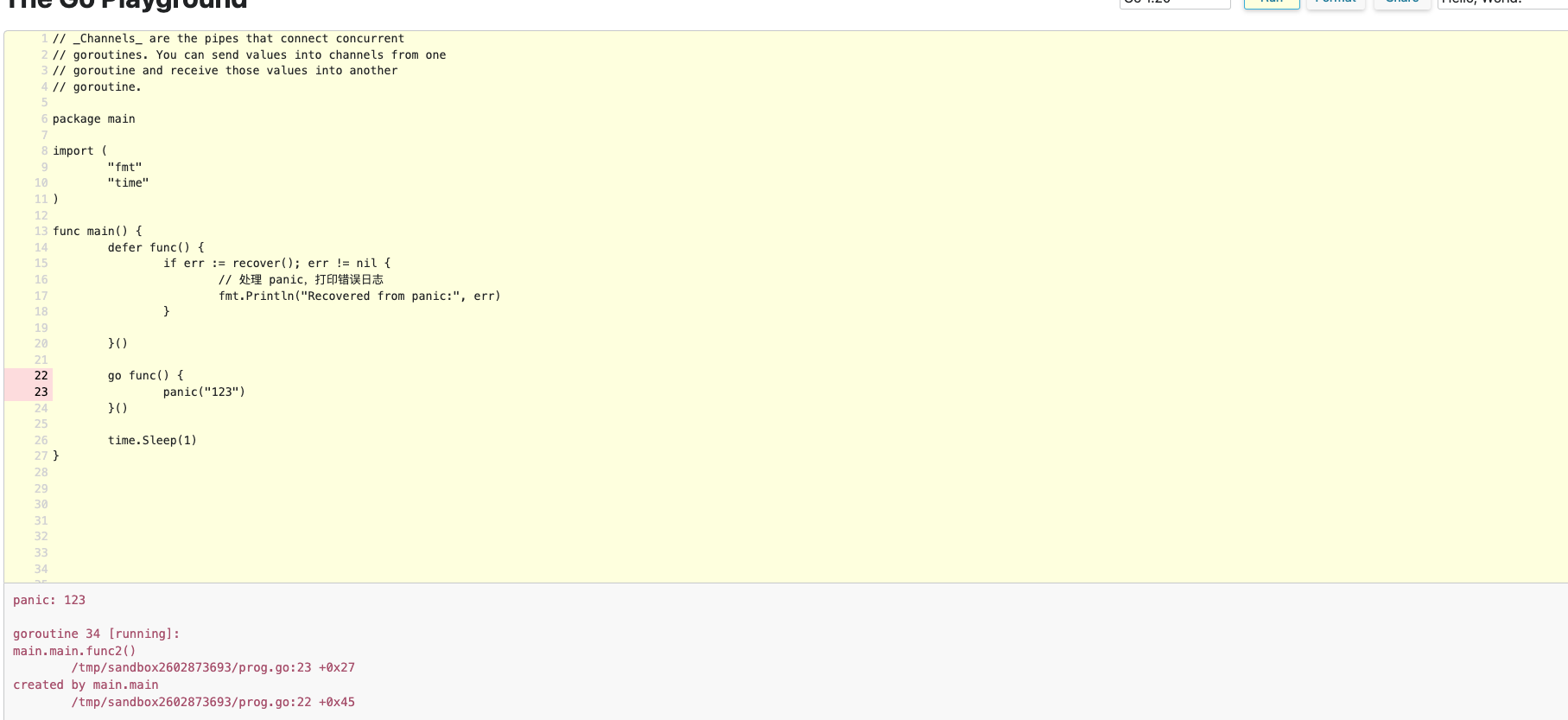
- 主 gouroutine 是无法 recover 子 gouroutine 的 panic 的。而 gdp 对于 request 的主 goroutine 有 recover panic. 但是在主 goroutine 里面开启的子 goroutine 里发生的 panic 会导致整个进程崩溃,所以开启 goroutine 一定要 recover. https://go.dev/play/p/2MocaKILQfK
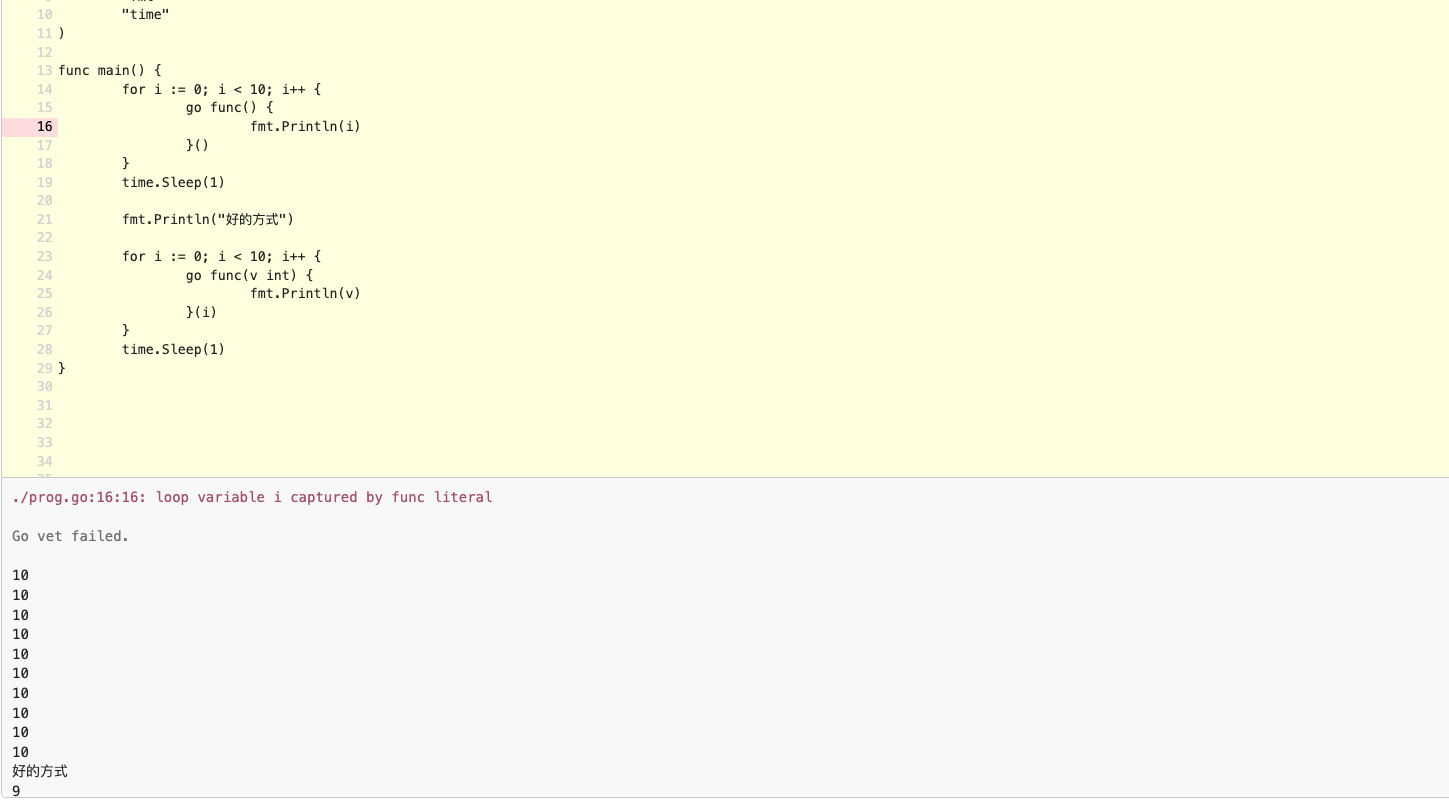
- 同时启动多个 goroutine 一定要通过匿名函数传参 https://go.dev/play/p/kDOKZEIRy90
- context
- golang 中 context 分为 timerCtx, valueCtx, emptyCtx 以及 cancelCtx. timerCtx 以及 cancelCtx 主要用来信号同步,比如 request 的超时控制。而 valueCtx 主要是用来值传递。
- timerCtx 和 cancelCtx 是如何进行超时/信号控制的。 https://go.dev/play/p/r_Y9gqqpItQ 一般涉及 io 读取的底层包,比如 ral, mysql driver 之类的底层都会监听 ctx.Done()(这是一个 channel), 一旦监听到退出信息(context has canceled)就会停止当前操作,进行取消。
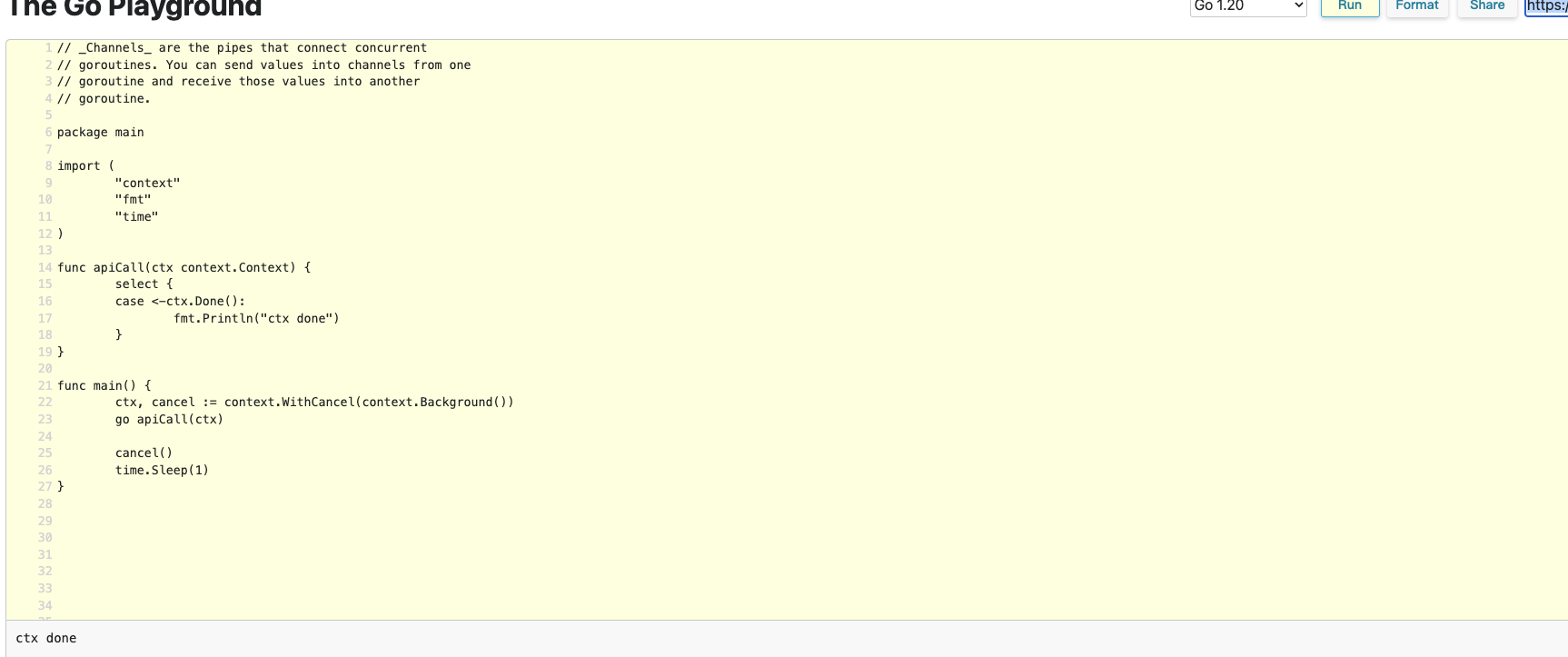
- 不监听 ctx.Done() 的 func 是没法做到取消和退出的。比如。对于不需要进行 api 调用/io 读写的函数不需要传递 ctx, 除非需要获取 ctx 里面值或者进行 tracing. 除了特殊需要,不要在同一个 request 里面开启新的 empty cotext. 包括 context.Background 和 context.Todo. 这会影响到超时控制,值传递以及 tracing。
func cal(a, b int) int {
return a + b
}
- 传递值一般通过 context.WithValue ,以及 context.Value 传递。比如我们在 plugin 层解析用户的 cookie 注入 userID. go 规范是不建议用 basic type, 例如 string 作为 context key 的。因为这可能会和其他包定义的碰撞。
- interface
golang 有 type interface 也有 interface{}(也就是 any), 前者是了多态场景的抽象,后者是一种空类型变量(可以赋值为任意的类型)。
- https://go.dev/play/p/XJASG4MxBQr type interface 可以用在具有相同一致行为的 struct 的抽象。
- interface{} 在某些场景下能够弥补 golang 本身的不灵活,但是 interface{} 也不能过多使用,当过多使用的时候这意味着我们放弃了编译型语言带来的类型安全,在运行时就可能会像 php 一样对于一个变量的类型是不确定的,这不仅会在写代码时带来认知成本或者错误使用的可能,在代码的运行过程中也会出现非预期的行为(本以为是个 map, 结果是 array)。所以,对于确定性的类型或者结构体就定义相应的结构体,golang 在写代码以及编译的过程中替我们做类型检查。而对于明确动态的场景,也可以将灵活性封装在模块内,对外部提供的接口/方法依然使用确定的类型。毕竟人生来就是犯错的,小概率的事情在多次试验的场景下就会发声,我们可能会出现不了解一个 inteface{} 的类型,它具体包含哪些字段,每个字段到底应该传什么类型的情况,而利用编译本身去约束这件事是更坚实的保证,这也是迁移 go 的意义之一。
举个例子:
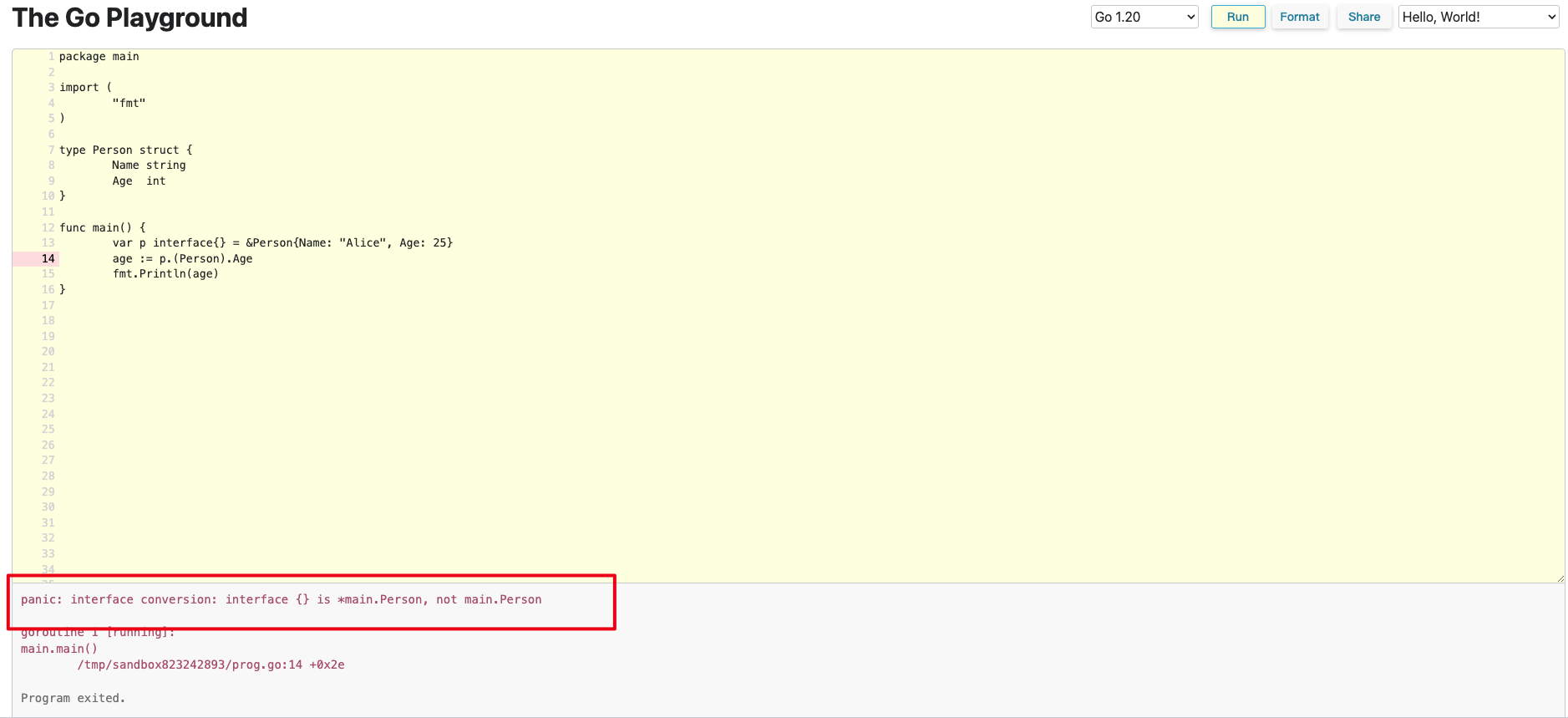
package main
import (
"fmt"
)
type Person struct {
Name string
Age int
}
func main() {
var p interface{} = &Person{Name: "Alice", Age: 25} // 因为传错类型而导致程序崩溃,只是因为多写了一个指针符号
age := p.(Person).Age
fmt.Println(age)
}
- defer
在 Golang 中,defer 关键字用于在函数返回时执行一些代码,无论函数是正常返回还是异常返回。defer 语句通常用于 recover panic, 释放资源、关闭文件、解锁 Mutex 等操作,以便在函数返回时进行清理工作。
defer 语句的执行顺序是后进先出(LIFO)的,也就是说,最后一个 defer 语句会最先执行,而第一个 defer 语句会最后执行。defer 参数的赋值是在执行时进行的 https://go.dev/play/p/SyAEKZNWFrF
- 泛型
泛型即不特定的数据类型,意味着相同的方法可以用于多种数据类型。当没有泛型时,对于 int 以及 float 类型的数据相加,你可能需要写多个函数,例如:
// SumInts adds together the values of m.
func SumInts(m map[string]int64) int64 {
var s int64
for _, v := range m {
s += v
}
return s
}
// SumFloats adds together the values of m.
func SumFloats(m map[string]float64) float64 {
var s float64
for _, v := range m {
s += v
}
return s
}
当有了泛型,你就只需要针对一类具有相同处理逻辑的数据类型写一个通用的方法
// SumIntsOrFloats sums the values of map m. It supports both int64 and float64
// as types for map values.
func SumIntsOrFloats[K comparable, V int64 | float64](m map[K]V) V {
var s V
for _, v := range m {
s += v
}
return s
}
错误处理
Golang 和 php 的错误处理有很大的差别。Golang 的错误是通过参数进行传播,是显式的,而 php 比较灵活,在我们的 php 工程中我们一般通过返回值是否为空或者为 false 进行判断的。同时 Golang 在问题排查方面没有 php 那么灵活,Golang 线上运行的是二进制包,无法通过临时修改代码来 debug. 所以在编写 golang 代码的时候尽量处理好 error 以及日志,这样能够帮助我们线上排查问题。
定义 error
- 定义一个 error
var ErrNoMoney error = errors.New("user doesn't have money") // 定义一个全局 error, 外部可捕获
type OrderError struct {
UserID int64
}
type User struct { // 通过 struct 定义 error 可以携带信息
UserID int64
}
func (o *OrderError) Error() string {
return fmt.Sprintf("user doesn't have money userid: %d", o.UserID)
}
func buy(balance int, product string, user User) error {
if balance < 0 {
return ErrNoMoney // return &OrderError{ UserID: user.UserID }
}
if len(product) == 0 {
return errors.New("invalid param")
}
data, err := json.Marshal(user)
if err != nil {
return fmt.Errorf("[buy] json marshal error %w", err)
}
}
上面我们通过 struct, 全局变量,以及函数内本地变量都定义过 error, 他们分别有不同的应用场景。
- 对于一个 error 全局变量来说,一般用于上层调用方需要捕获/断言的场景(比如这个 error 是对业务有意义的,需要业务进行特殊处理)
var ErrNoMoney error = errors.New("user doesn't have money")
func upstream() {
err := buy()
if err != nil && errors.Is(err, ErrNoMoney) { // 这里就是在捕获 error
fmt.Println("用户没钱了,需要回滚库存扣减")
} else if err != nil {
fmt.Printf("未知错误 %s\n", err.Error())
}
}
func buy() error {
return ErrNoMoney
}
- 对于一个 struct 定义 error 的场景, 跟 error 全局变量类似,也是用于需要捕获 error 的场景。但是通过 struct 定义可以携带更多信息,并且这些信息也能被断言。通过一个 error struct 定义一类 error. 比如 https://github.com/lib/pq/blob/381d253611d666974d43dfa634d29fe16ea9e293/error.go#L11 对 postgresql 的错误是这样抽象
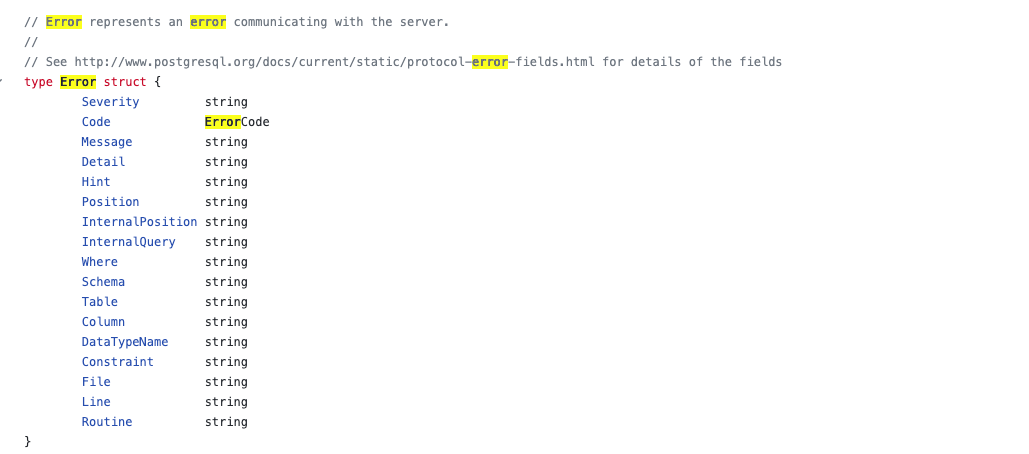
对这类 error 的断言通过这种方式
type PGError struct {
Code int
Msg string
}
func (p *PGError) Error() string {
return fmt.Sprintf("pg error code: %d, msg: %s", p.Code, p.Msg)
}
func do() {
err := execSQL()
if pe := new(*PGError); errors.As(err, &pe) {
fmt.Printf("error code is %d \n", pe.Code)
}
}
func execSQL() error {
return &PGError{ Code: 80001, Msg: "upsert conflict" }
}
- 对于非预期的 error/外部不需要捕获的 error, 可以直接在行内声明和返回
func do(userID int) error {
if userID <= 0 {
return errors.New("invalid param")
}
return nil
}
Wrap error
为什么 Error wrap 是有意义的,当 error 没有经过 wrap ,这意味着这样的 error 没有上下文信息(调用链路+有效参数)。试想一个有成本上千 api 的项目,项目按照 controller, service, api adapter/repo 分层的项目,日志里都是 invalid connection/io timeout 的报错。根本无法判断是哪个接口甚至哪个接口里的哪行代码出了错,虽然全链路日志(通过 logid 串联)一定程度可以解决这个问题。所以尽量保证 wrap error 能够提供完整的链路信息和有效入参。
没有 wrap error 的坏处
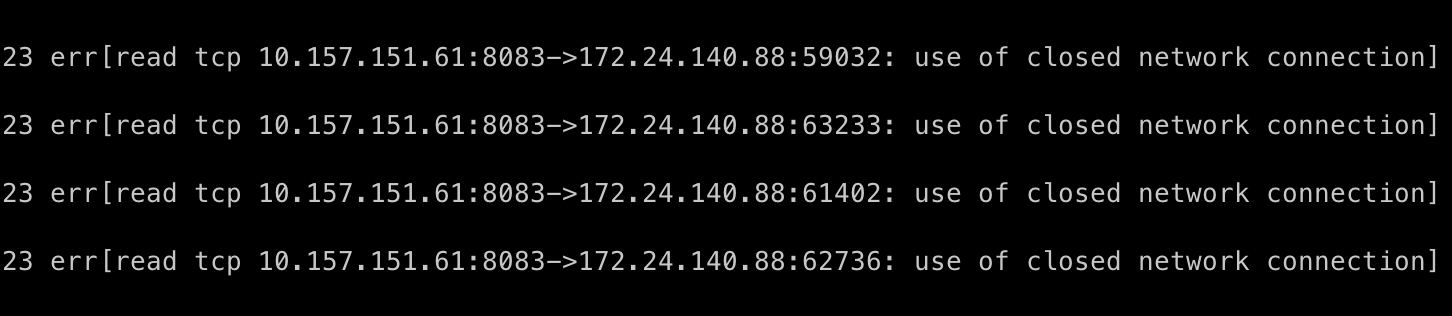
func do() error {
_, err := json.Marshal(&a)
if err != nil {
return err
}
_, err := json.Marshal(&b)
if err != nil {
return err
}
}
// 当 marshal failed 发生时你很难知道到底是哪行出了问题
好的方式
func buy(userID int) error {
_, err := store.New()
if err != nil {
return fmt.Errorf(
"new store, userID: %d, err: %w", userID,err)
}
return nil
}
new store, userID: 123, err: the error // 打印出来的 error 会是
对于底层返回来的 error 我们基本都是需要 wrap 的,只有我们不想上层捕获底层错误的时候这时候才会返回一个新的 error, 比如自定义过一个全局变量 error, error struct 等。而我们一般在 controller/bs 层对 error 进行统一处理的(大多数场景下你不需要在底层的 service/library 等地方再打日志,除非有特殊的需要)
丢弃 error
在大部分场景,都不应该直接丢弃 error. 除非输入是固定/写死的,而且是经过验证的。Golang error 处理确实比较麻烦,但是在排查问题的时候当 error 被丢弃掉,这意味着基本无法发现错误的原因和地点。
我们对错误出现的场景都是在做有限假设,虽然我们能够确保我们假设的场景里不会出现 error, 但是我们无法确定我们超出我们预期的场景,比如网络中断,缓冲区溢出等等,当这些问题发生的时候,并且这样的 error 被丢弃掉,这意味着大量的排查时间或者逐渐被掩盖/忽视的问题。又或者某些业务场景不重要,对业务影响不大,不需要对用户暴露错误的场景,这些我们直接抛弃 error 也不是永远正确的,当产品发现这个功能不 work 的时候,你也很难判断这是预期的还是异常的。错误处理本身是为了开发的便利性,它不应该被认为是负担。具有不同重要性场景的错误可以通过分级日志或者在告警规则侧做后置处理,错误现场需要尽可能还原信息。
我们不能假设所有场景都是按照预期去工作的,我们需要去思考它出问题的场景,会对什么造成影响,以及我们如何去发现这个问题和原因。被直接抛弃的 error 并没有被悄悄地修复了,只是被忽视到了视线以外。
什么时候 panic
在运行时(api 请求 etc.)不应该 panic, 需要通过 error 传播去处理某种异常情况。而在服务启动初始化资源的时候去使用 panic, 对于重要资源的启动初始化失败的场景一定要使用 panic, 没有 panic 而服务正常启动并运行的话这意味着会带来很多副作用(错误的配置导致大量的脏数据,数据库未初始化成功导致 api 一直 500 etc.)。
避免踩坑
- gorm 的零值忽略, 所以尽力避免业务上的枚举值定义为 0,否则这既可能代表未初始化又可能代表用户显式设置的 0 值。
Golang struct 在未赋值的时候默认都是零值。string 的零值是 “”, int 的零值是 0。gorm 在使用 struct 更新的时候会默认忽略 0 值。比如你显式想将一个字段从 1 更新为 0,会不成功。
// Update attributes with struct, will only update non-zero fields
db.Model(&user).Updates(User{Name: "hello", Age: 18, Active: false})
// UPDATE users SET name='hello', age=18, updated_at = '2013-11-17 21:34:10' WHERE id = 111;
// Update attributes with map
db.Model(&user).Updates(map[string]interface{}{"name": "hello", "age": 18, "active": false})
// UPDATE users SET name='hello', age=18, active=false, updated_at='2013-11-17 21:34:10' WHERE id=111;
- gorm, 通过 RowsAffected 判断更新是否成功
// Get updated records count with `RowsAffected`
result := db.Model(User{}).Where("role = ?", "admin").Updates(User{Name: "hello", Age: 18})
// UPDATE users SET name='hello', age=18 WHERE role = 'admin';
result.RowsAffected // returns updated records count
result.Error // returns updating error
- nil 可能不是 nil https://go.dev/play/p/iQYOTpCENWq
- 资源未关闭导致内存泄漏
虽然 go 是一个有 gc 的语言,大部分场景下未关闭的资源都能够被正常回收,导致未关闭的资源可能导致其他 goroutine 阻塞(比如 channel), 所以资源在开启以后一定要关闭,最好通过 defer 关闭(包括文件 io, 网络 io 以及 channel 等)。
- make([]string, 10) 后使用 append 赋值 https://go.dev/play/p/LhJASE32TuP
- 避免返回 nil, nil
在 go 规范里我们一般通过 error 判断是否有异常/返回值是否有效,如果 error 为 nil 我们则认为返回值是有效的,nil, nil 会导致额外的判断。
- internal 路径下的导出类型/方法只能被同一个根目录下的代码引用,这通常被用来代码访问控制
An import of a path containing the element “internal” is disallowed if the importing code is outside the tree rooted at the parent of the “internal” directory.
For example:
- Code in /a/b/c/internal/d/e/f can be imported only by code in the directory tree rooted at /a/b/c. It cannot be imported by code in /a/b/g.
- $GOROOT/src/pkg/internal/xxx can be imported only by other code in the standard library ($GOROOT/src/).
- $GOROOT/src/pkg/net/http/internal can be imported only by the standard net/http and net/http/* packages.
- $GOPATH/src/mypkg/internal/foo can be imported only by code in $GOPATH/src/mypkg.
测试
测试基本分为两大类,一类是单元测试,一类是集成测试。但单测的结构基本是一致的,包括数据准备,执行以及断言。断言需要对结果正确性进行判断,对于 mock 测试,还需要对 mock 方法执行次数进行断言。
单元测试
- 旨在屏蔽各种外部依赖(api/数据库/底层函数),对 func 进行独立测试。对有外部依赖的 func 一般通过 mock 进行测试,go mock 依赖的方式有两种,一种是通过定义的 interface 生成一个 mock struct, 这类的工具有 https://github.com/golang/mock 。这种要求工程里必须有 interface. 另一种方式是通过运行时内存打桩实现的,这类代表有 https://github.com/bytedance/mockey . 针对数据库等各种存储依赖也是可以进行单元测试的,比如 sqlmock https://github.com/DATA-DOG/go-sqlmock 和 https://github.com/go-redis/redismock, 他们本质都是基于原有对象的 interface 实现了一个 mock 类。
interface mock:
typeFoointerface {
Bar(xint) int
}
funcSUT(fFoo) {
// ...
}
funcTestFoo(t*testing.T) {
ctrl:=gomock.NewController(t)
// Assert that Bar() is invoked.deferctrl.Finish()
m:=NewMockFoo(ctrl)
// Asserts that the first and only call to Bar() is passed 99.// Anything else will fail.m.
EXPECT().
Bar(gomock.Eq(99)).
Return(101)
SUT(m)
}
内存打桩
import (
"fmt"
"testing"
. "github.com/bytedance/mockey"
. "github.com/smartystreets/goconvey/convey"
)
func Foo(in string) string {
return in
}
type A struct{}
func (a A) Foo(in string) string { return in }
var Bar = 0
func TestMockXXX(t *testing.T) {
PatchConvey("TestMockXXX", t, func() {
Mock(Foo).Return("c").Build() // mock function
Mock(A.Foo).Return("c").Build() // mock method
MockValue(&Bar).To(1) // mock variable
So(Foo("a"), ShouldEqual, "c") // assert `Foo` is mocked
So(new(A).Foo("b"), ShouldEqual, "c") // assert `A.Foo` is mocked
So(Bar, ShouldEqual, 1) // assert `Bar` is mocked
})
// mock is released automatically outside `PatchConvey`
fmt.Println(Foo("a")) // a
fmt.Println(new(A).Foo("b")) // b
fmt.Println(Bar) // 0
}
集成测试
一般通过 docker compose 起实例(mysql, es)来生成一个运行环境,一般只对 repo/dao 层做集成测试,其他层都做单元测试。
go 测试还有个特殊的地方在于它倡导 table driven tests. 比如
func TestCheckURLWhiteLists(t *testing.T) {
type args struct {
url string
whitelist []string
}
tests := []struct {
name string
args args
want bool
}{
{
name: "url完全匹配白名单",
args: args{
url: "inner/checkContentCompliance",
whitelist: []string{"inner/checkContentCompliance"},
},
want: true,
},
{
name: "url满足白名单正则",
args: args{
url: "inner/checkContentCompliance",
whitelist: []string{"inner/*"},
},
want: true,
},
{
name: "*",
args: args{
url: "inner/checkContentCompliance",
whitelist: []string{".*"},
},
want: true,
},
{
name: "url不匹配",
args: args{
url: "inner/checkContentCompliance",
whitelist: []string{"internals/*", "inner/blacklist"},
},
want: false,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := CheckURLWhiteLists(tt.args.url, tt.args.whitelist); got != tt.want {
t.Errorf("CheckURLWhiteLists() = %v, want %v", got, tt.want)
}
})
}
}
go 工具
- 使用 gvm(golang version manager) 进行 go 安装和版本管理:https://github.com/moovweb/gvm
- 使用 golangci-lint 进行代码检查,golangci-lint 不仅仅只是语法风格的检查,还可以对可能的 bug 进行提醒(用了弱加密,sql 注入,不安全的包以及不可寻址的变量等等)Golang lint 101
- 性能测试,golang 最简单的性能测试方法就是在单测中进行 benchmark, 比如:
// main.go
func primeNumbers(max int) []int {
var primes []int
for i := 2; i < max; i++ {
isPrime := true
for j := 2; j <= int(math.Sqrt(float64(i))); j++ {
if i%j == 0 {
isPrime = false
break
}
}
if isPrime {
primes = append(primes, i)
}
}
return primes
}
// test
package main
import (
"testing"
)
var num = 1000
func BenchmarkPrimeNumbers(b *testing.B) { // 注意这里是 testing.B, 意味着 benchmark
for i := 0; i < b.N; i++ {
primeNumbers(num)
}
}
benchmark 结果:
$ go test -bench=. -count 5
goos: linux
goarch: amd64
pkg: github.com/ayoisaiah/random
cpu: Intel(R) Core(TM) i7-7560U CPU @ 2.40GHz
BenchmarkPrimeNumbers-4 14485 82484 ns/op
BenchmarkPrimeNumbers-4 14557 82456 ns/op
BenchmarkPrimeNumbers-4 14520 82702 ns/op
BenchmarkPrimeNumbers-4 14407 87850 ns/op
BenchmarkPrimeNumbers-4 14446 82525 ns/op
PASS
ok github.com/ayoisaiah/random 10.259s
- 内存泄漏排查, 在本地可以通过 https://github.com/uber-go/goleak 检查内存泄露,在线上可以通过 pprof gdp框架下pprof使用 观察。
func TestMain(m *testing.M) { // 注意这里是 testing.M, testing.M 是当前包下的测试函数入口,一般 testing.M 用来进行测试的准备工作,比如在集成测试里用来准备数据,启动环境等等
goleak.VerifyTestMain(m)
}
- 检查 data race, 在多 goroutine 读取/写入线程不安全变量的时候,会导致 data race, 导致程序崩溃,可以使用
go test -race ./...或者go build -race main.go检查
WARNING: DATA RACE
Write at 0x00c0000a2028 by goroutine 7:
main.main.func1()
/path/to/main.go:16 +0x44
Previous read at 0x00c0000a2028 by goroutine 6:
main.main.func2()
/path/to/main.go:22 +0x44
Goroutine 7 (running) created at:
main.main()
/path/to/main.go:15 +0x9c
Goroutine 6 (finished) created at:
main.main()
/path/to/main.go:21 +0x76
- 观测性生态
现在问题排查的痛点:
-
- 出现问题了,很难感知到。
- 知道出现问题了,不知道应该去哪里排查(上哪台机器,看哪个日志文件)
- 找到错误日志了,但是信息不够全面,很难得出结论
- 有统计分析日志的需要,但是太多机器执行太复杂
- 性能优化不知道瓶颈在哪里,不知道一个 api 的哪个操作耗时最长
- 涉及到重构与迁移的时候,需要看代码才能理清整个服务调用链路,有些外部依赖不确定是否在使用
解决这些痛点的方案:
1. 日志统一集中存储到日志平台,日志平台可以进行日志的查询。日志平台可以通过关键字模糊搜索,以及通过 logid 等进行日志检索。同时可进行日志统计分析
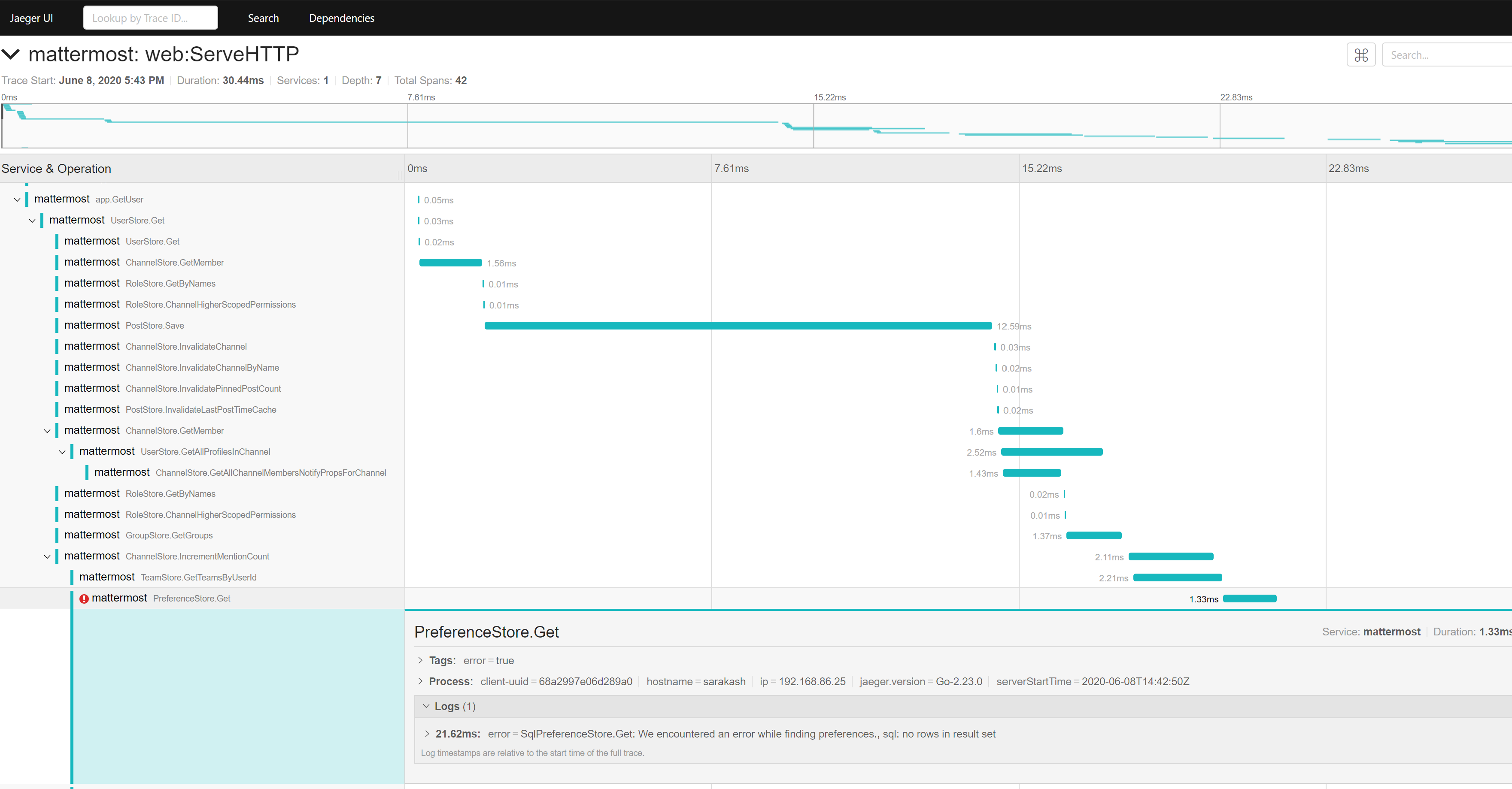
2. 引入 Distributed tracing, 可以图示化整个链路的请求路径/耗时/错误。
- 利用 go playground 做原型验证或者分享代码 https://go.dev/play/
- golang 社区规范参考: https://github.com/uber-go/guide/blob/master/style.md