背景信息
爱企查从 23 年 5 月份开始逐步探索 AI 在站内的应用。探索的方向包括针对当前已有场景进行 AI 重构,以及借助 AI 创造新的功能场景,激发创造新的用户需求。
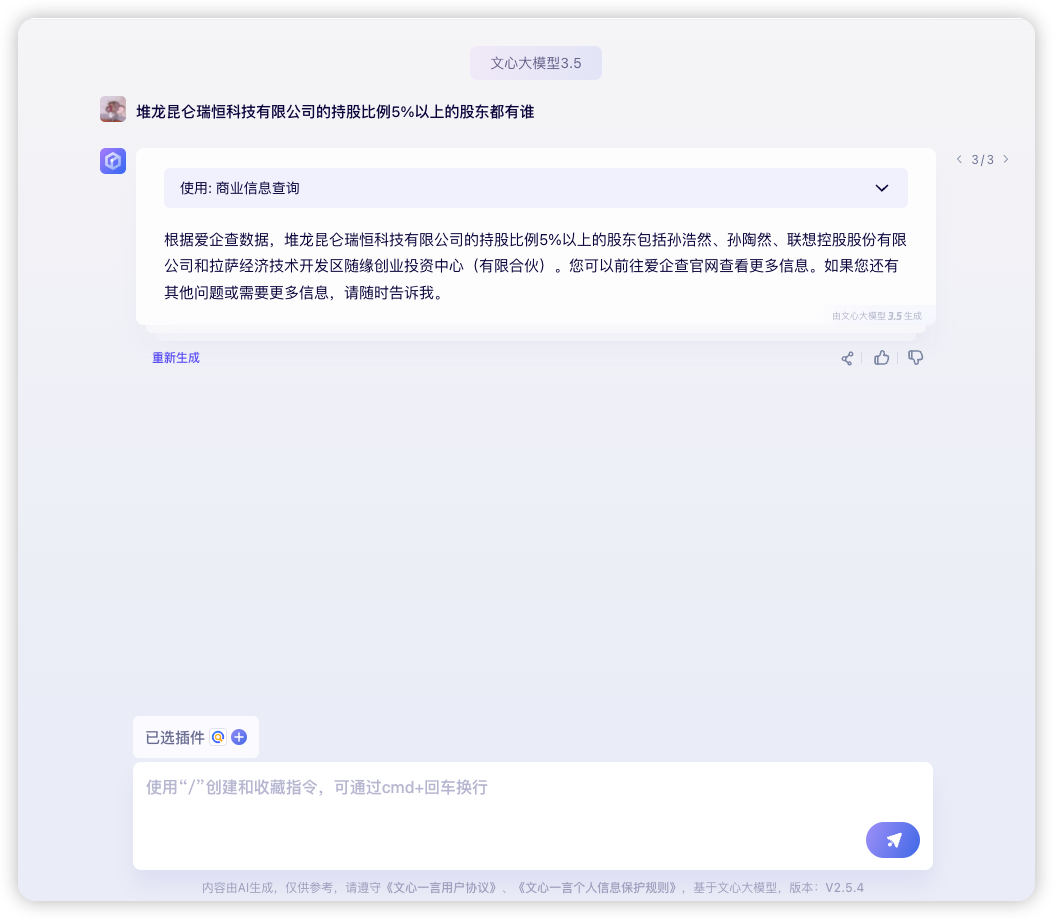
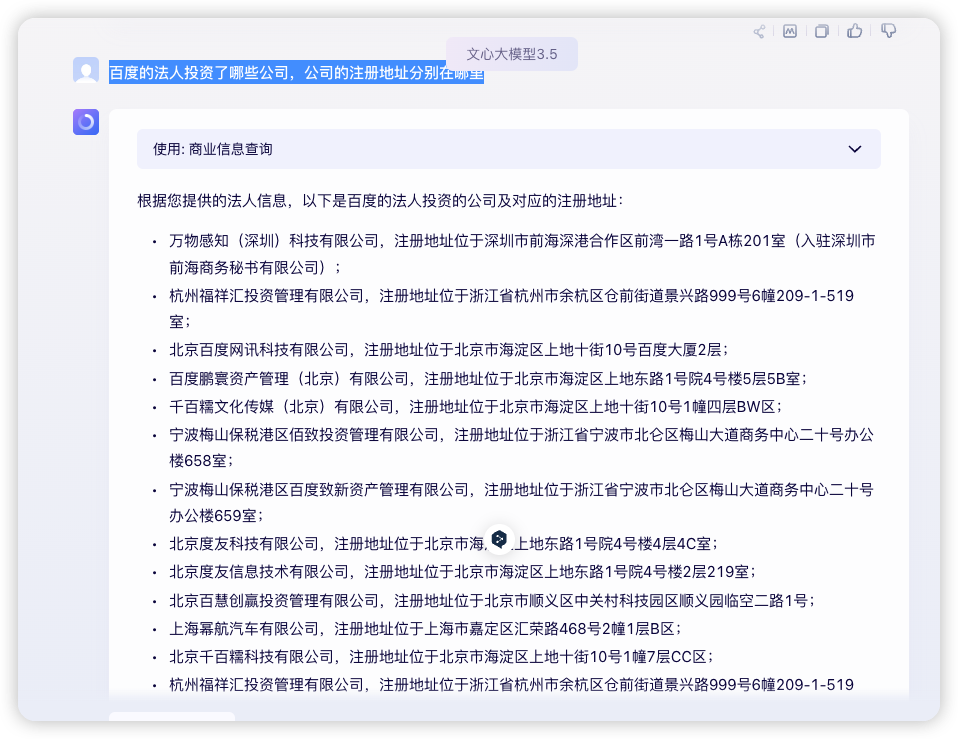
爱企查作为一个信息查询工具,从查询信息的方式上,数据的组织和交互形式都是非个性化和固定的,用户需要对产品和领域具有一定的了解。而基于 AI 打造的智能查询工具,则能够以自然语言地形式进行交互,不同知识背景的用户都能够按照自己习惯的方式得到满足,并且大模型能够基于已有信息进行延展分析和总结,能够满足高价值且长尾的需求。基于发挥大模型的优势,更好地满足用户个性化的需求,爱企查基于文心一言搭建了一个企业信息知识图谱,当前已经使用在了一言的商业信息查询插件以及站内的 copilot 企业助手两个场景上。
从满足用户需求的层面上看,查询企业信息是整个用户需求满足过程中一个手段和步骤,用户查询信息的目的可能是采购商品,招投标尽调,品牌加盟咨询等。产品形态上,同时具备信息查询+供需撮合的产品较少,同时,该场景下的线索具有较大的商业价值,当前爱企查站内已经具有可观的该类线索,所以完成从信息查询工具到工具+供需社区的转型对爱企查而言是很大一个机会和挑战。想要做到供需双方的满足,既要激发用户需求同时又要补充供给。在用户需求的激发和收集上,使用文心一言能够基于用户的诉求提供灵活和个性化的引导方式,从而丰富线索的信息的维度,并提高线索的质量,同时,基于智能客服的形态也能够整合站内的资源,在对话中根据用户诉求和站内资源的匹配情况适时推荐。通过多维度能力的建设,我们最终孵化了 copilot 企业助手。
知识图谱
知识图谱是基于文心一言+图数据库的自然语言信息检索工具,旨在通过自然语言的交互形式进行数据的查询。
当前共支持 70+类的企信数据维度,涵盖 7.5 亿人员/企业等节点数据,15 亿投资/任职等边关系数据。
查询类型上共支持检索企业属性,人企关系,通过属性检索企业,多人员/多企业,基于关系的多跳查询等查询方式。


为什么采用知识图谱的 RAG 方案
当前流行的 RAG 方案包括向量检索,知识图谱,基于大模型加持的传统数据库等。
| 方案 | 知识图谱 | 向量检索 | 基于大模型加持的传统数据库 |
|---|---|---|---|
| 数据存储 | 类似 kv 的三元组 | 需要经过内容切分,qa 对生成等步骤 | 一般宽表 |
| 是否支持推理 | 支持,知识图谱能够根据边关系进行推理,同时也能依赖大模型的知识进行推理 | 只能依赖大模型的知识进行推理 | 只能依赖大模型的知识进行推理 |
| 是否支持基于关系的多跳查询 | 支持,性能好 | 不支持 | 需要 join,耗费性能 |
| 复杂查询的性能(例如:通过属性查找主体) | 一般 | 好 | 不好 |
| 检索结果粒度的控制能力 | 好 | 不好 | 好 |
从数据存储的角度来说,爱企查站内的已有数据多类似三元组的结构,即 主体 id + 数据维度 + dataid 的形式,因此从数据存储结构的迁移和处理上,知识图谱的灌库成本更小。
从查询的角度来说,站内数据量极大且用户的查询类型多样,传统关系型数据存在性能瓶颈,扩展难度大。虽然向量检索性能较好,但是仅限于语义相关性检索,不支持基于关系多跳查询以及查询推理等。而知识图谱无论在查询类型支持以及性能上,都相对较优。
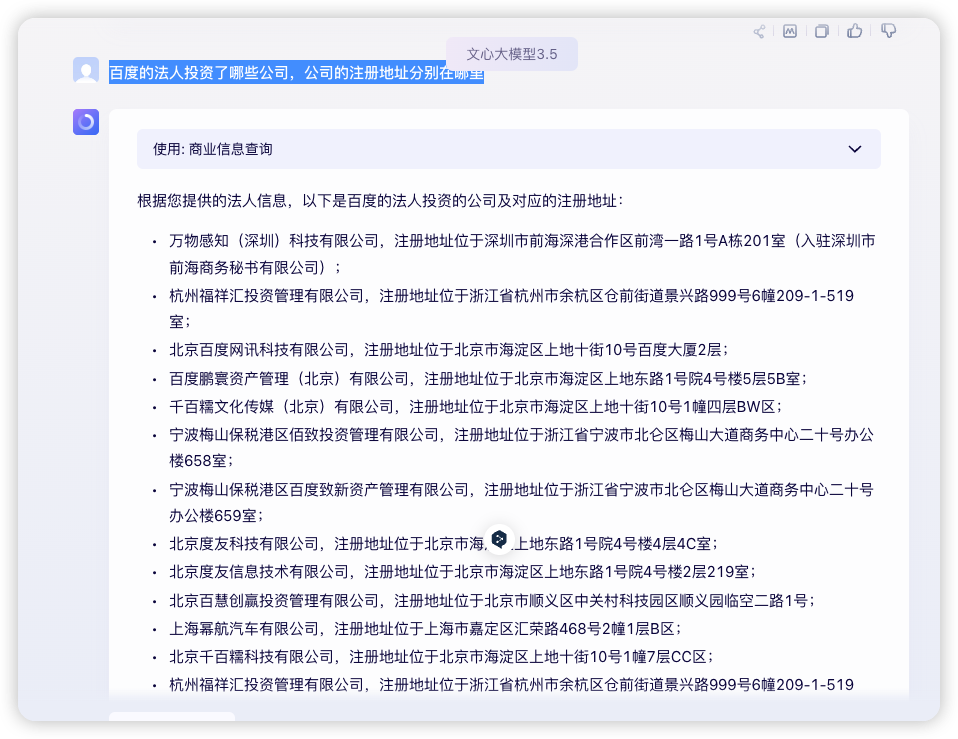
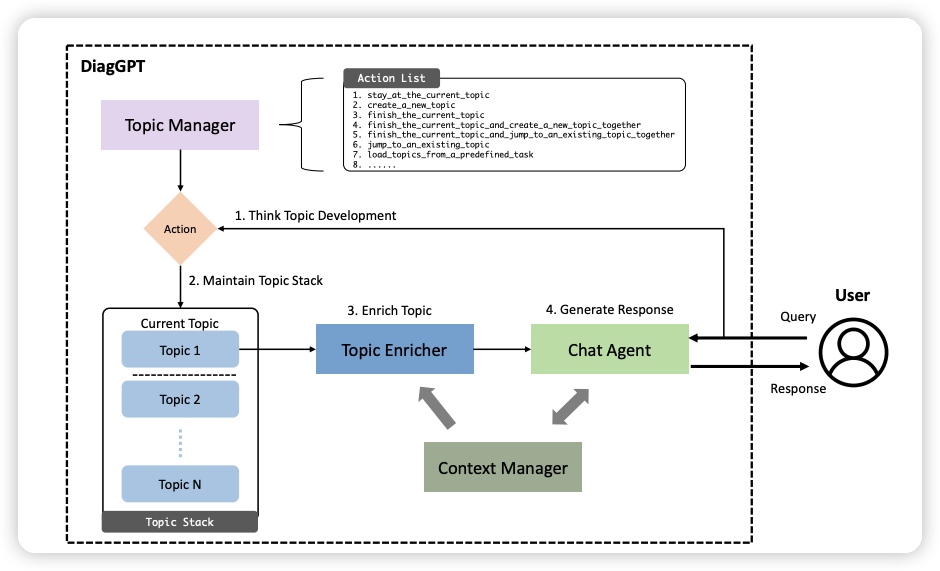
项目架构
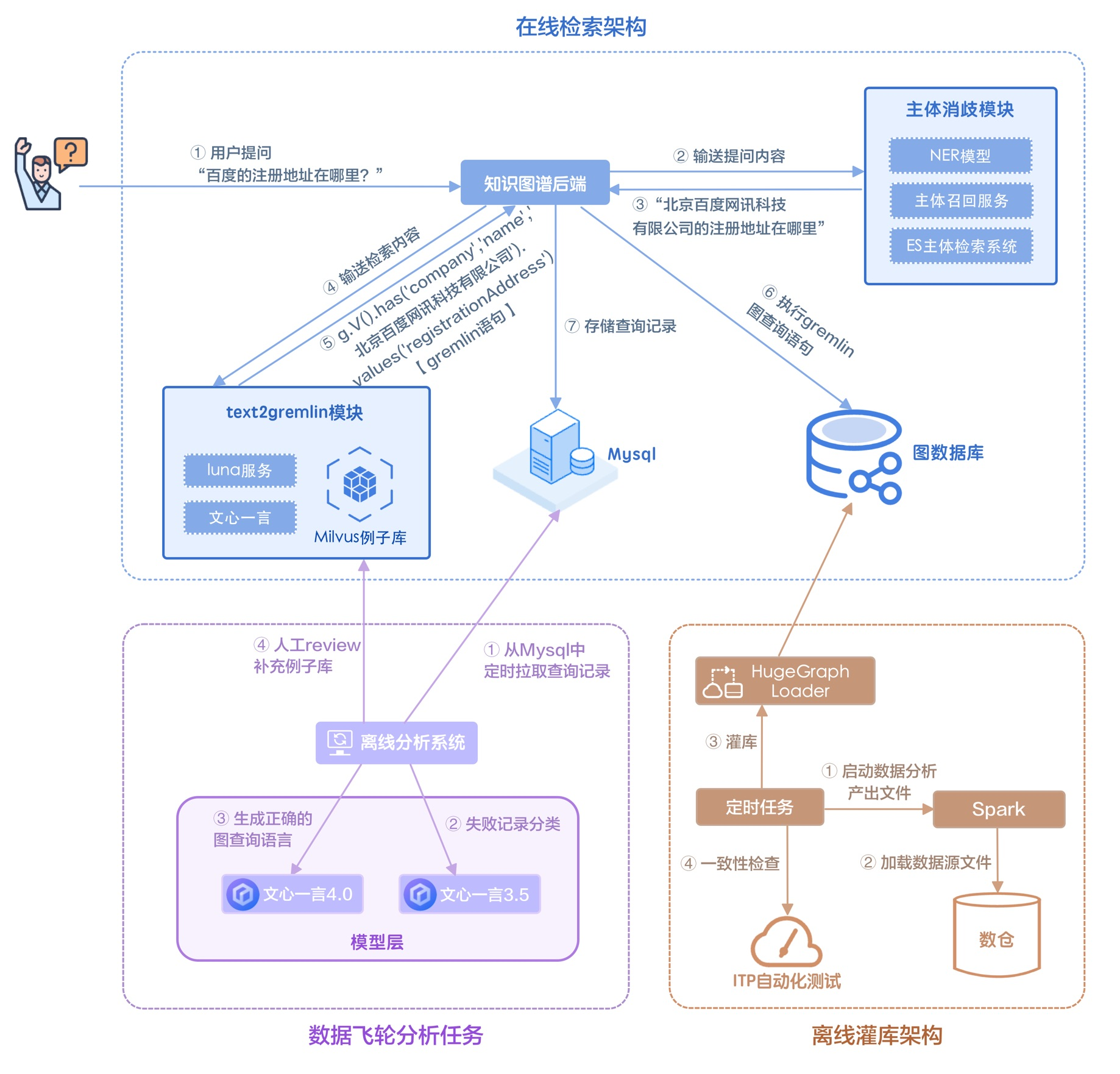
执行过程拆解
消歧过程
消歧是指针对用户问题中存在的指代词和歧义词通过澄清或者基于语义理解的替换等手段使用户问题与已有的主体或者意图链接的过程。整个消歧包括指代消解 -> 主体检索两个步骤。例如:
- 百度的注册地址在哪里。问题中的百度可能指百度网讯,百度在线等多家公司主体,而进行实际的数据查询前需要确定具体的查询主体。
- 他们的法人是谁。他们是一个指代词,在一个多轮对话中,需要根据上下文进行语义理解,从而对指代词进行消解。
- 指代消解:基于 eb3.5 根据历史对话内容对当前用户的问题进行指代消解。
你是一名内容改写AI,专门针对用户的问题进行指代消解。对于每个问题,根据以下任务步骤执行:
1. 首先阅读历史对话,判断 user 的最后一条消息是否需要进行指代消解。
2. 如果需要,根据历史对话中的信息替换指代词(例如: 你们)或者补全消息中缺失的内容,然后输出处理后的 user 最后一条消息。
3. 如果不需要,则直接输出原始的 user 最后一条消息。
#### 例子 START ####
例子1:
assistant:欢迎来到百度网讯有限公司
user:你们的电话号码是多少
输出: :{ "question": 百度网讯有限公司的电话号码是多少 }
例子2:
assistant:欢迎来到无锡爱美丽公司
user:可以提供下电话吗
输出:{ "question": 可以提供下无锡爱美丽公司的电话吗 }
#### 例子 END ####
#### 历史对话 START ####
#### 历史对话 END ####
#### 输出格式 START ####
{
"question": string, //指代消解过的问题 or 原始问题
}
#### 输出格式 END ####
输出:
指代消解完成后可以基本确保问题中不存在指代词以及语句残缺。完成指代消解后,需要进行主体词消歧。
- 主体消歧:基于 NER ,NLPC 以及 es 的主体检索系统。
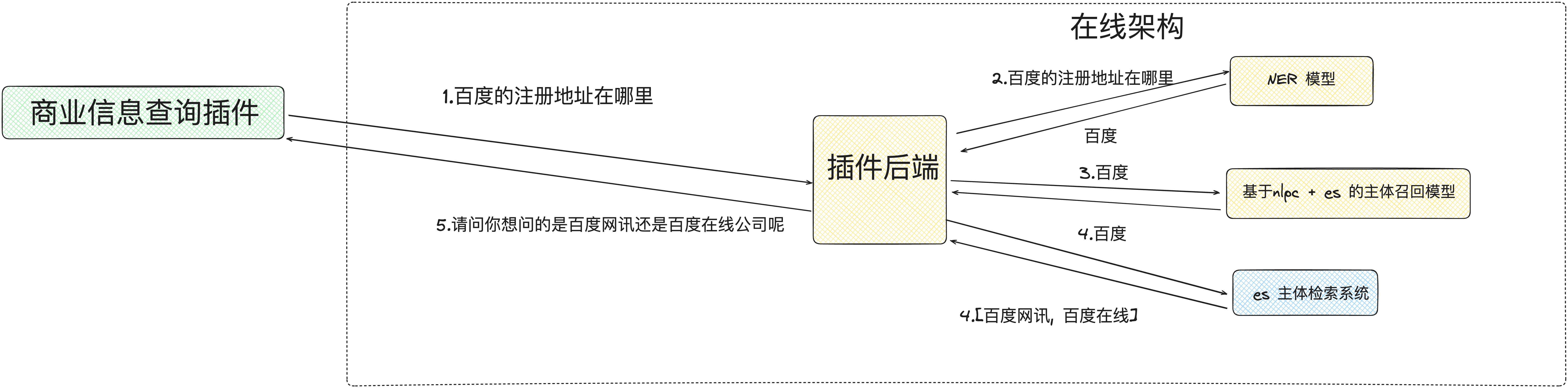
消歧过程的第一步是使用 NER 模型针对用户问题进行切词,从用户问题中提取出公司名称。然后使用 nlpc + es 的主体召回服务进行主体精准匹配,如果匹配成功则能够获得对应企业主体的完整名称和企业 id,消歧完成。
如果 nlpc + es 未能精准匹配到任何企业,则触发 es 模糊搜索,倘若同时搜索到多个企业,则会追问用户,引导用户确认。
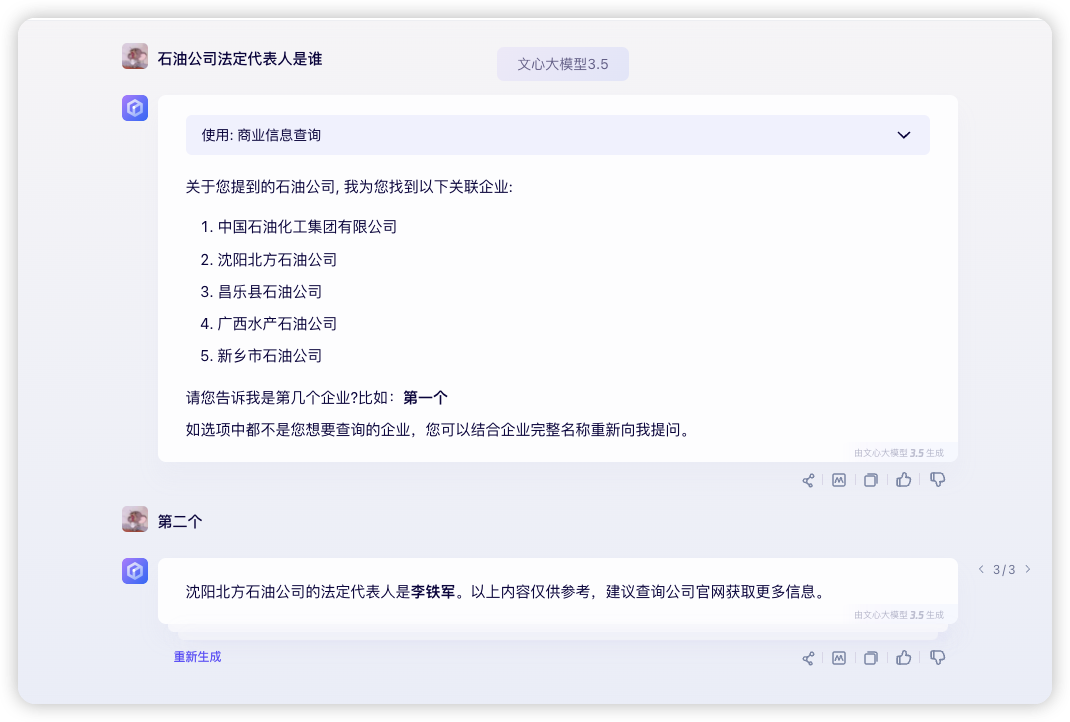
消歧过程完成后则可以保证用户问题中的主体是明确且唯一,并在图谱中可被检索的。
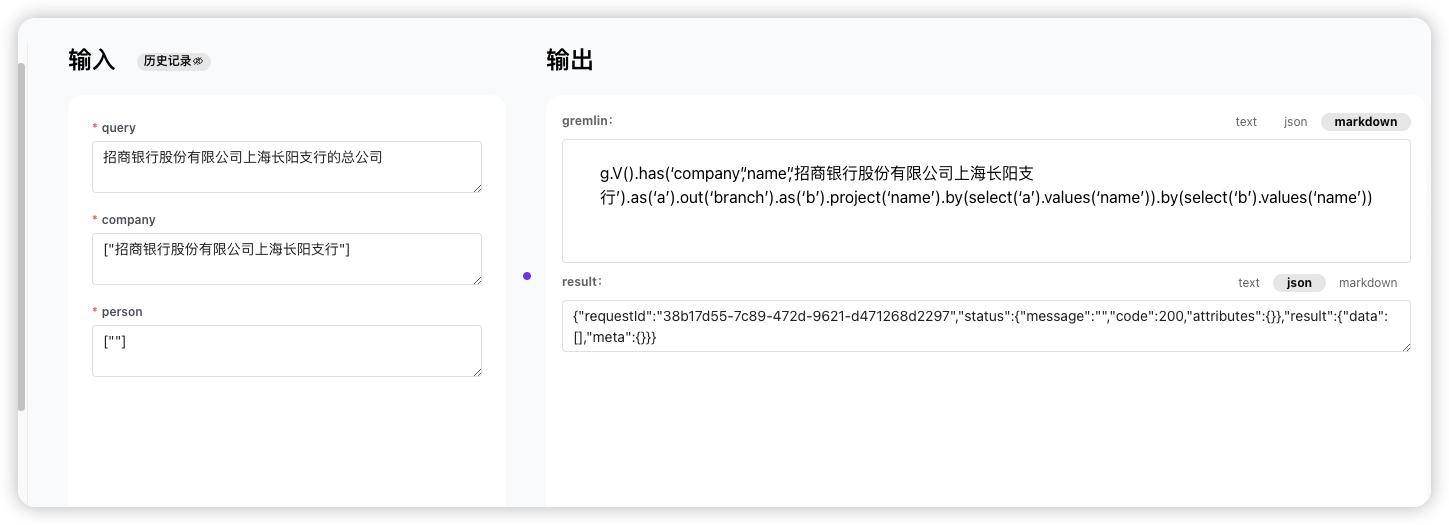
Text2gremlin 过程
Text2gremlin 主要是通过 few-shot 的方式依靠 eb3.5 转换用户问题为 gremlin 查询语句。
您是一位专业数据分析师,为企业查询设计了一套Hugegraph数据库。
{schema_info}
【任务】您需要根据用户的问题做一个查询任务,写出gremlin查询语句。
【要求】
1,写查询数据库语句,不是修改数据库,不可以修改数据库
2,给出的gremlin语句与上述数据库信息不冲突,不可幻想新字段,不可幻想新的边
3,仅在问题后给出gremlin语句,不要任何解释。
4,如果所写gremlin语句存在错误,您会给开除,因此,请仔细检查您的gremlin语句。
{examples}
【问题】:{query}
【回答】:
其中 examples 是基于用户问题从例子库中召回的相似例子。所有的例子为了避免因为主体名称带来检索相关性的负面效果,都使用了 Masked Question Similarity Selection 的方式,即都采用相同的企业主体名称。
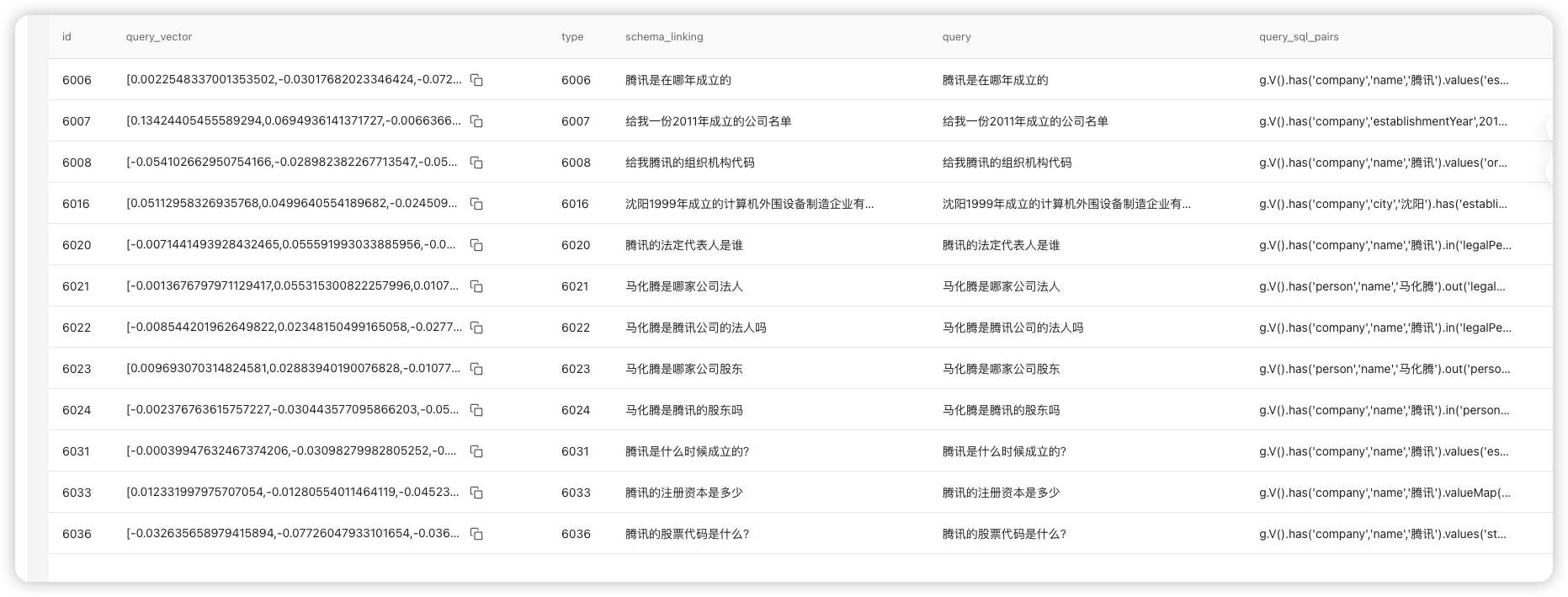
灌库过程
图库灌库当前采用的是双图切换的方式,即图库同时存在两张图,但是指针始终指向通过验证的图。在线服务查询数据时,直接通过指针查询对应的图库。而离线灌库时,首先查询指针指向,然后灌入非指向图,在灌库完成后在线下插件环境执行图谱自动化测试,测试通过则执行指针切换。
ITP 自动化测试目前共包含 185 个测试 case,涵盖了知识图谱当前支持的所有数据维度,通过对知识图谱查询结果进行断言从而判断数据准确性,确保灌库数据的完整性。

Copilot 企业助手
Copilot 企业助手是基于大模型的智能客服,能够为用户提供加盟,采购类的服务咨询,同时也能够基于站内的信息针对投诉以及信息查询等场景的提供建议。从内容生成和交互的角度,Copilot 助手基于用户的意图进行不同方向的对话引导,引导方向包含收集用户信息,回答用户问题以及处理售后反馈等。同时结合站内的商品推荐,企业名录和供需集市等功能从多维度满足用户的需求。
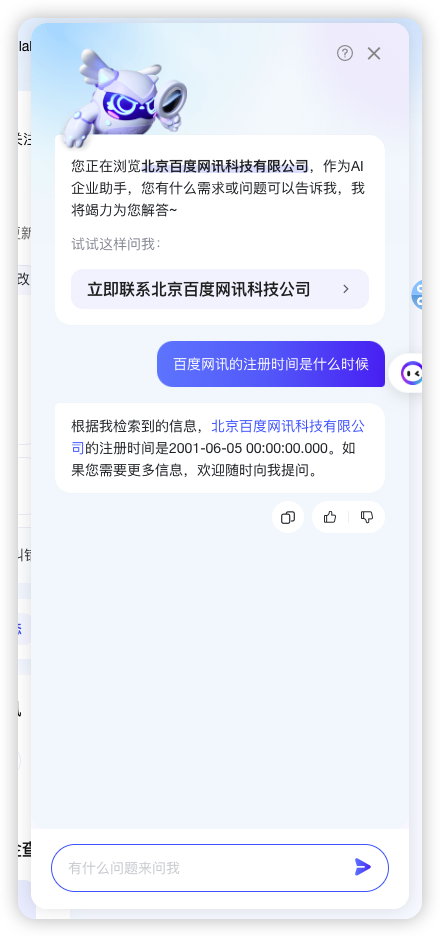
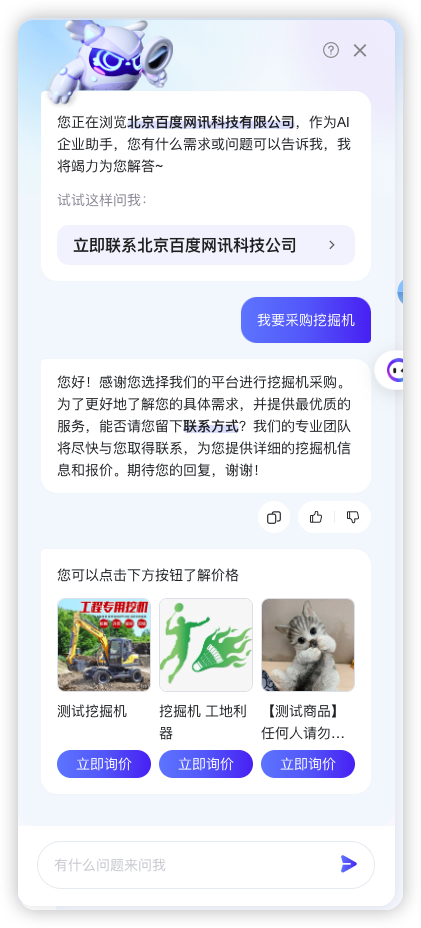
项目架构
Copilot 的对话模块主要基于 Directional-Stimulus-Promting 的手段进行基于不同场景的对话生成,整个对话过程大致包含行动建议生成 -> 相关知识检索 -> 回复生成三个步骤。

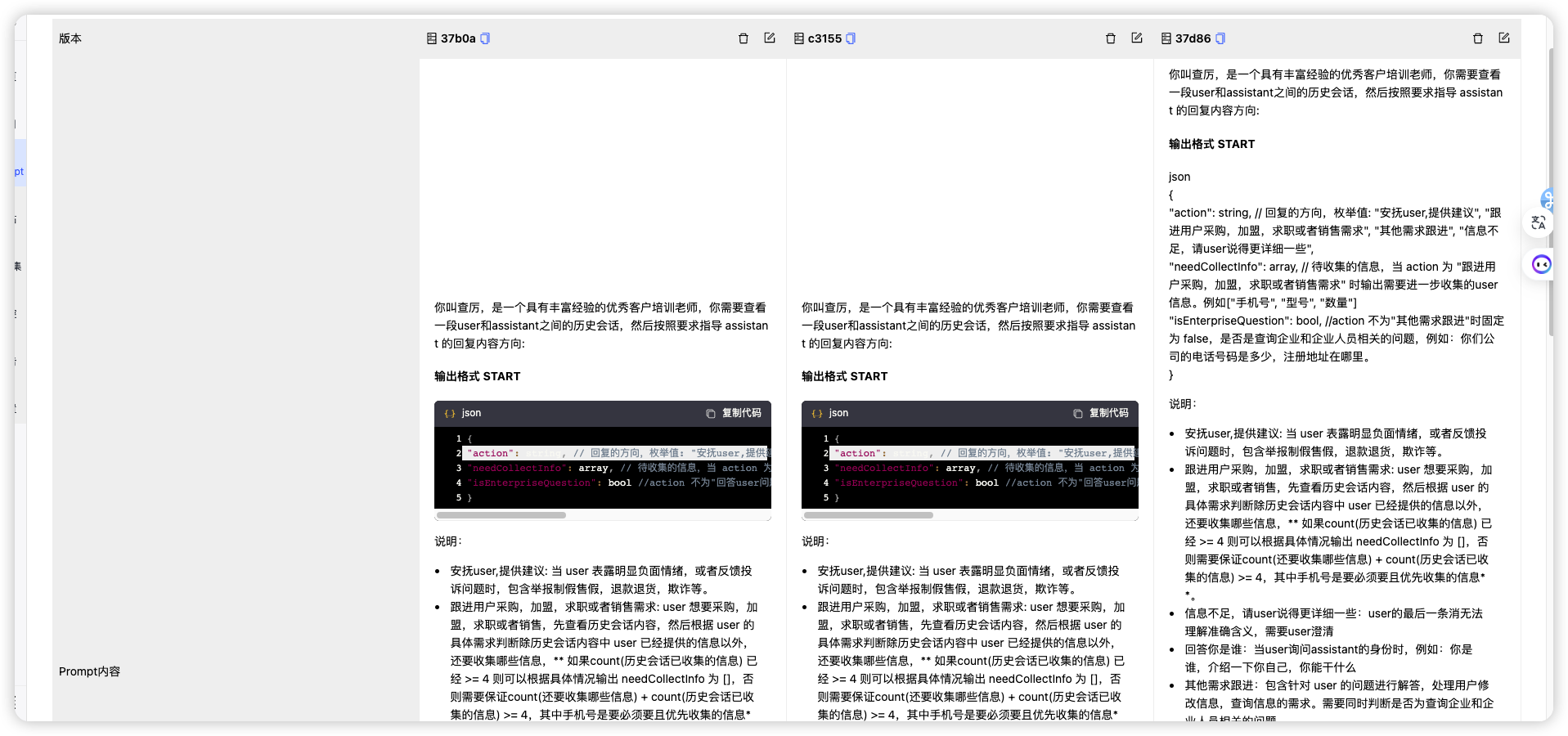
行动建议 prompt:
你叫查厉,是一个具有丰富经验的优秀客户培训老师,你需要查看一段user和assistant之间的历史会话,然后按照要求指导 assistant 的回复内容方向:
#### 输出格式 START ####
json
{
"action": string, // 回复的方向,枚举值: "安抚user,提供建议", "跟进用户采购,加盟,求职或者销售需求", "其他需求跟进", "信息不足,请user说得更详细一些",
"needCollectInfo": array, // 待收集的信息,当 action 为 "跟进用户采购,加盟,求职或者销售需求" 时输出需要进一步收集的user信息。例如["手机号", "型号", "数量"]
"isEnterpriseQuestion": bool, //action 不为"其他需求跟进"时固定为 false,是否是查询企业和企业人员相关的问题,例如:你们公司的电话号码是多少,注册地址在哪里。
}
说明:
- 安抚user,提供建议: 当 user 表露明显负面情绪,或者反馈投诉问题时,包含举报制假售假,退款退货,欺诈等。
- 跟进用户采购,加盟,求职或者销售需求: user 想要采购,加盟,求职或者销售,先查看历史会话内容,然后根据 user 的具体需求判断除历史会话内容中 user 已经提供的信息以外,还要收集哪些信息,** 如果count(历史会话已收集的信息) 已经 >= 4 则可以根据具体情况输出 needCollectInfo 为 [],否则需要保证count(还要收集哪些信息) + count(历史会话已收集的信息) >= 4,其中手机号是要必须要且优先收集的信息**。
- 信息不足,请user说得更详细一些:user的最后一条消无法理解准确含义,需要user澄清
- 回答你是谁:当user询问assistant的身份时,例如:你是谁,介绍一下你自己,你能干什么
- 其他需求跟进:包含针对 user 的问题进行解答,处理用户修改信息,查询电话等信息的需求。需要同时判断是否为查询企业和企业人员相关的问题
#### 输出格式 END ####
#### 样例 START ####
#### 样例 END####
#### 历史对话 START ####
#### 历史对话 END ####
无论如何,请严格按照 action 的值定义输出。
回答:
收集信息 prompt:
作为AI企业助手,我是一位富有经验且专业的客服专员。我们平台致力于满足 user 的各类需求,包括采购、销售、加盟、服务咨询以及招聘服务等。我们的企业联系电话是:。主要经营项目涵盖:等等。运营品牌包括:等等。在接下来的对话中,我将**引导 user 提供**以更好地为他服务。
我将**引导 user 提供**以更好地为他服务。
对话:
回复:
assistant:
针对 AI 应用的研发流程优化
针对 AI 应用的开发,在落地上面临几大挑战。其中一大挑战是可观测性不足,模型基本是一个黑盒,虽然我们清楚模型生成内容是一个拟合过程,但是我们无法按照预期量化地度量和调整模型,我们只能通过测试观测其行为,当前市面上有一些教程和 prompt 相关的编写方式,但是这不能形成完整的实践方式。另一方面是没有较成熟的产品可以参考,因此产品的效果和成本很难获得先验的判断。所以整体需要更好地做到原型探索以及系统化的评估才能控制成本和效果。爱企查侧在不断地摸索过程中在研发流程做了一些探索和优化。

多探索,以小成本试错。探索和原型验证的阶段主要是利用 pandas 低代码平台,pandas 平台提供了搭建 llm 应用常用的工具,能够比较快速地搭建一个 llm 应用。在知识图谱方案的探索以及 copilot 优化的过程中,都有利用 pandas 验证方案的可行性。

评估单元化和系统化。prompt 的管理则主要依赖于 ievalue, ievalue 提供 prompt 的生成,优化,评估和管理等功能。在爱企查历史开发的过程中,面临的一个痛点是 prompt 很多,难以管理,以及 prompt 优化难以做到全面评估以及版本间对比。 而 ievalue 提供了一系列功能解决了上述痛点。它支持评估集评估,多版本间评估比较以及版本发布等功能。
集成后同样为了保证评估的全面性,也搭建了基于评估集的自动化测试,评估集来源于线上数据,其中包含待优化的 case 以及正例 case。对话模块的自动化测试的结果会经过人工 review,针对不符合预期的 case 通过 trace 进行分析。