智能客服技术
智能客服技术的发展
在讲智能客服技术之前,先简单谈一下客服行业。客服是一个服务性质的岗位,是产研和客户之间的反馈渠道,客服的出现是为了解决用户体验和产研认知产生冲突的地方,同时也负责衔接体验流程的断点(比如,线上下单外卖后,线下配送问题的跟进)。对内,客服是产研接受外部反馈的一种渠道,对外,客服代表企业履行服务职责。
客服的核心目标就是支持和帮助用户解决问题,保障用户体验,而这使客服部门也成为了企业的成本中心。为了追求更高的用户满意度,以及降本增效,客服行业经历了数字化,智能化的演进。数字化主要包括接触点的增加以及问题处理流程的在线化,首先用户的反馈渠道从仅有的电话扩充到如今的网站,电话,社交媒体等多种渠道,同时工单,质检,外呼等系统的建设,帮助客服独立且及时地解决用户问题。而智能化则主要是依托 AI 的能力替代或辅助客服,不仅能提升问题响应速度,同时也能帮助企业节省成本。


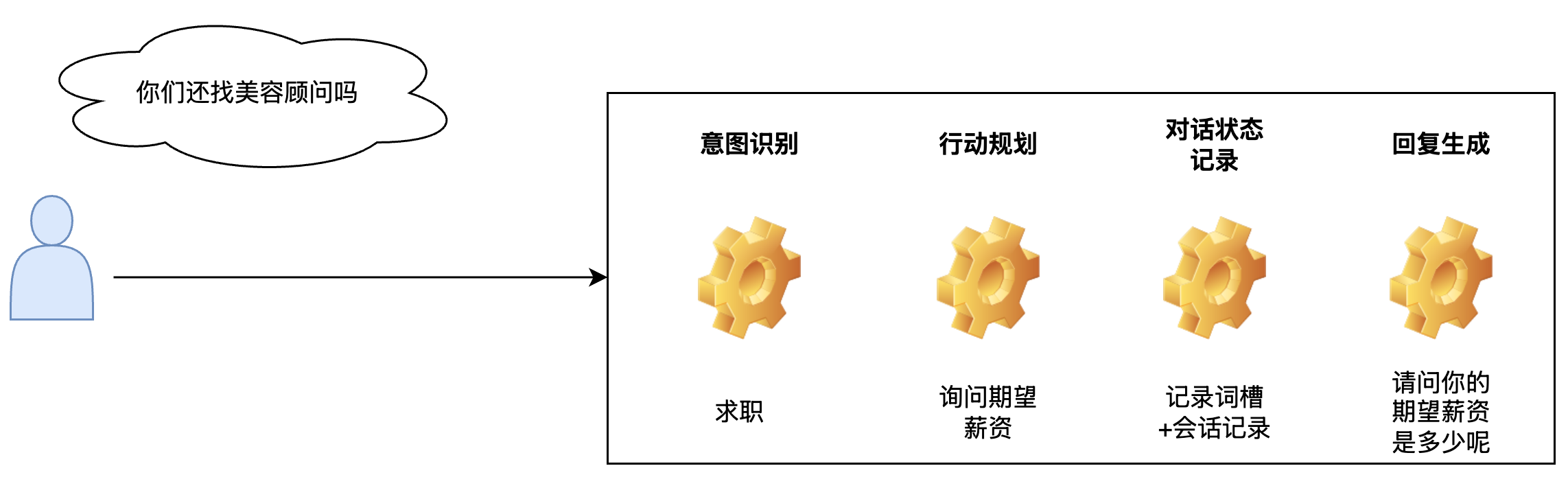
智能客服按照对话模式可以分为任务式对话,检索式对话和闲聊三种。检索式对话是指基于相关的资料完成问题解答,在基于大模型的智能客服架构下,检索式对话主要通过 RAG 的方式完成有参考回复。任务式对话旨在帮助用户完成特定的任务或目标。这种对话系统通常聚焦于提供信息、执行操作或解决问题,一种通过 pipeline 的实现方式包含意图识别,词槽提取,对话状态跟踪以及决策制定等步骤,而另一种则是端到端的解决方案,例如通过一个 prompt 完成前述所有的步骤(copilot 早期的版本)。一个智能客服可能具备以上一种或多种对话模式,这一般要视业务需要而决定。

但是很遗憾,智能客服产品领域内的对话,是一个非常典型的限定业务领域、任务驱动的对话需求,我们客户肯定不希望访客进来,是寻找一个超高智能、善解人意、能写会画的陪聊机器人。
会话内容必须收敛于企业业务范畴内,服务于客服和营销场景下,解决和处理问题,不要浪费宝贵的资源。
不加控制的直接引入ChatGPT到客服领域,那感觉就好比你回家撞见扫地机器人不干活,和隔壁的智能吸尘器聊的你侬我侬,是不是恨不得一棒子打死了事!
智能客服针对不同的应用场景又可以分为售前/中/后的服务型客服,营销客服以及陪伴类客服,针对上述不同类型的客服在行业内有如下不同的考核指标。
| 客服类型 | 北极星指标 |
|---|---|
| 售前、售后等服务型智能客服 | 独立接待率或转人工率 |
| 陪聊智能客服 | 陪聊市场、用户活跃市场 |
| 营销智能客服 | 营销转化率 |
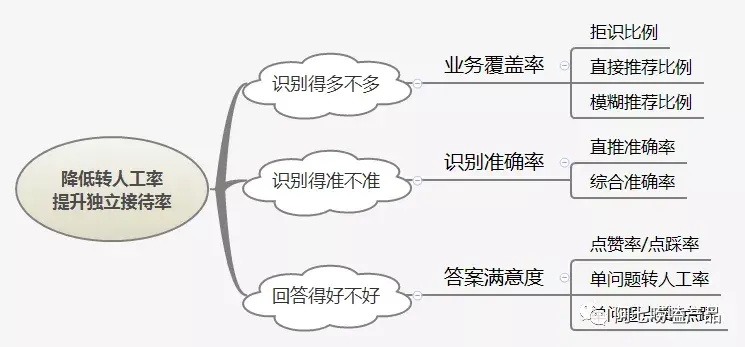
针对服务型的机器人,影响最终用户体验以及转人工率的关键因素包含业务覆盖率,识别准确率,答案满意度三个因素。业务覆盖率是指机器人知识库能够覆盖更多业务问题,当业务覆盖率越高,机器人就能识别更多意图,解答更多业务问题。识别准确率是指机器人直接正确回复的消息数+机器人间接推荐相关问题的消息数占总消息数的比例。答案满意度一般通过单问题转人工率/赞踩率以及整体赞踩率去衡量,另一种方式则是通过运营人工评估来间接反映(即拨测准确率)。
以我们的实践来看,拨测准确率的数据比问题识别率要低3-4个点,即在90%左右的水平。
https://cloud.tencent.com/developer/article/1673160
Copilot
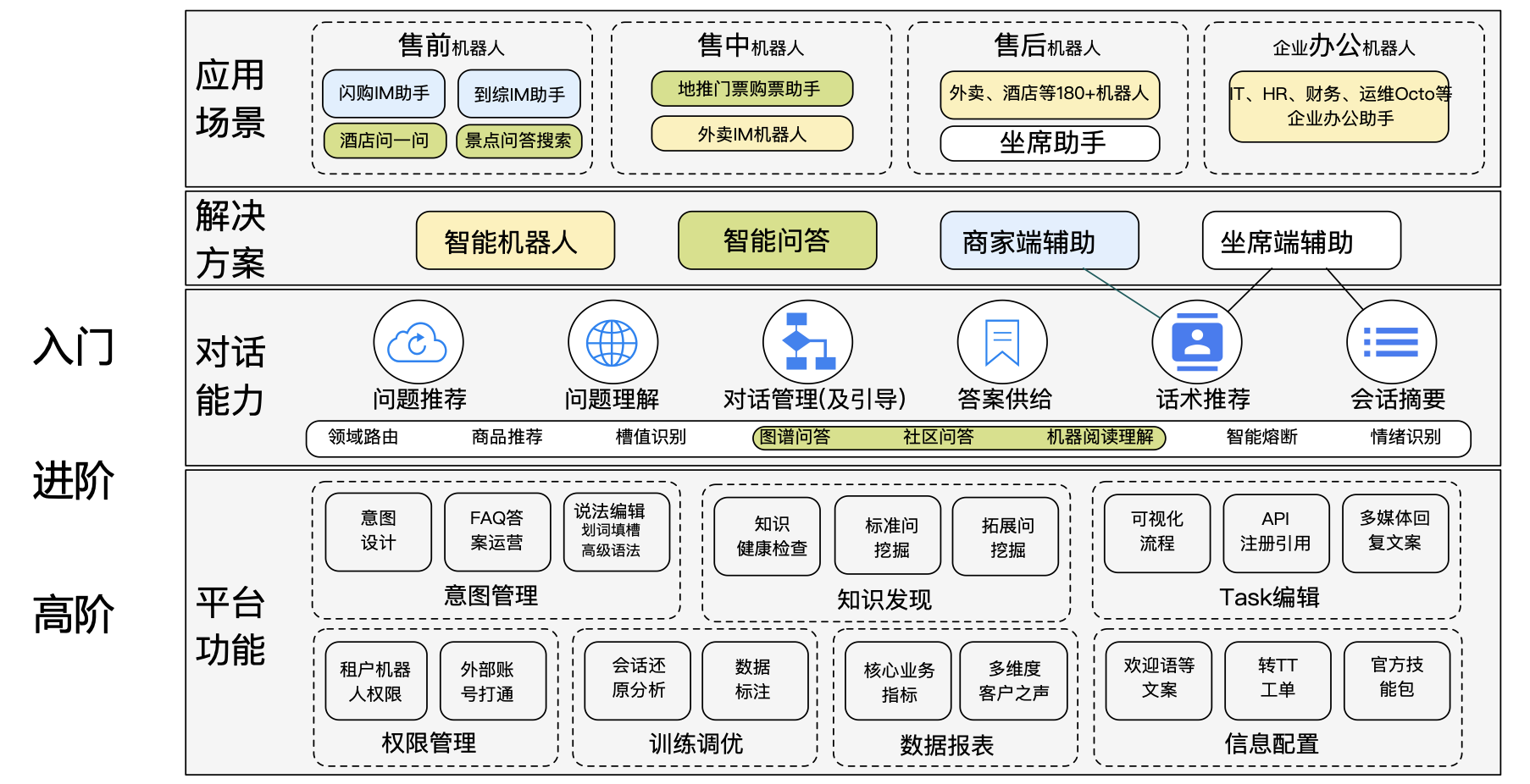
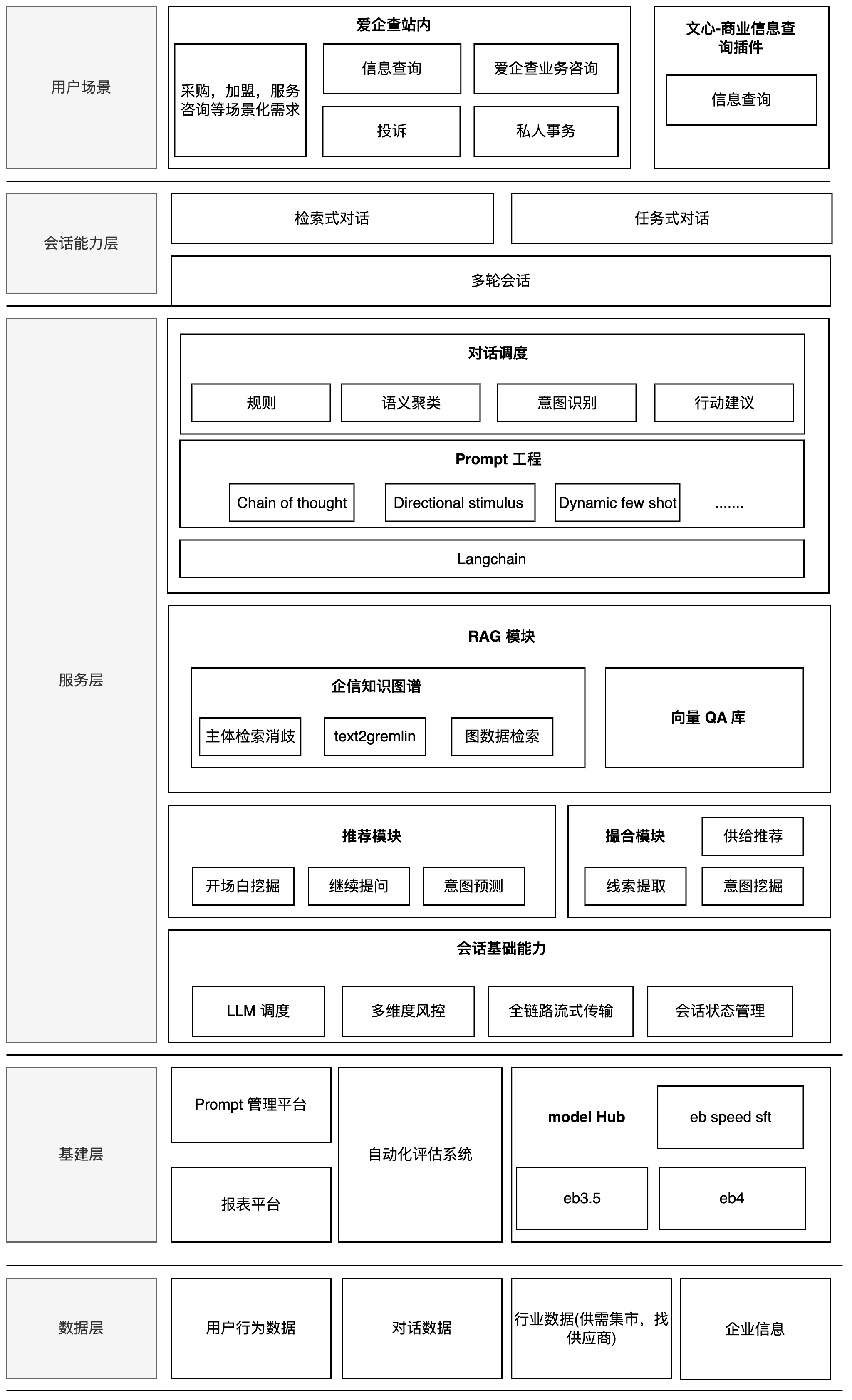
右侧图为 copilot 的当前架构图,所有的对话能力主要围绕两个应用(Copilot 企业助手以及商业信息查询插件),五个用户场景来搭建任务式对话以及检索式对话的能力。对比左侧美团智能客服的架构,在对话模块的整体架构上大同小异。在检索式问题这块,美团同时包含 PGC,UGC还有MGC数据,分别是平台自提信息,社区问答信息以及入驻商家维护信息,这保证了问题覆盖率。而 Copilot 只拥有爱企查的企业信息数据以及部分b2b行业数据,相比用户的问题空间来说有效的数据支持有限(用户会询问一些非企业信息领域的问题),因此我们针对问题的领域进行了分类,针对能回答的企业信息问题进行站内知识检索,针对无法回答的用户问题提供用户企业联系方式或通过百度搜索提供参考信息。在任务式对话这块,美团平台上包含需求端,平台方以及供给端,自身就具备了前后链路问题解决的能力,因此,用户的需求通过领域识别模型匹配对应的流程模板,基于流程模板收集和识别用户信息触发退款,换餐等操作。相比美团,爱企查当前的后链路并不完善,不具备站内解决用户诉求的能力,因此当前的任务式对话主要基于用户的需求尽可能收集更多的需求信息,以供后链路撮合和满足。
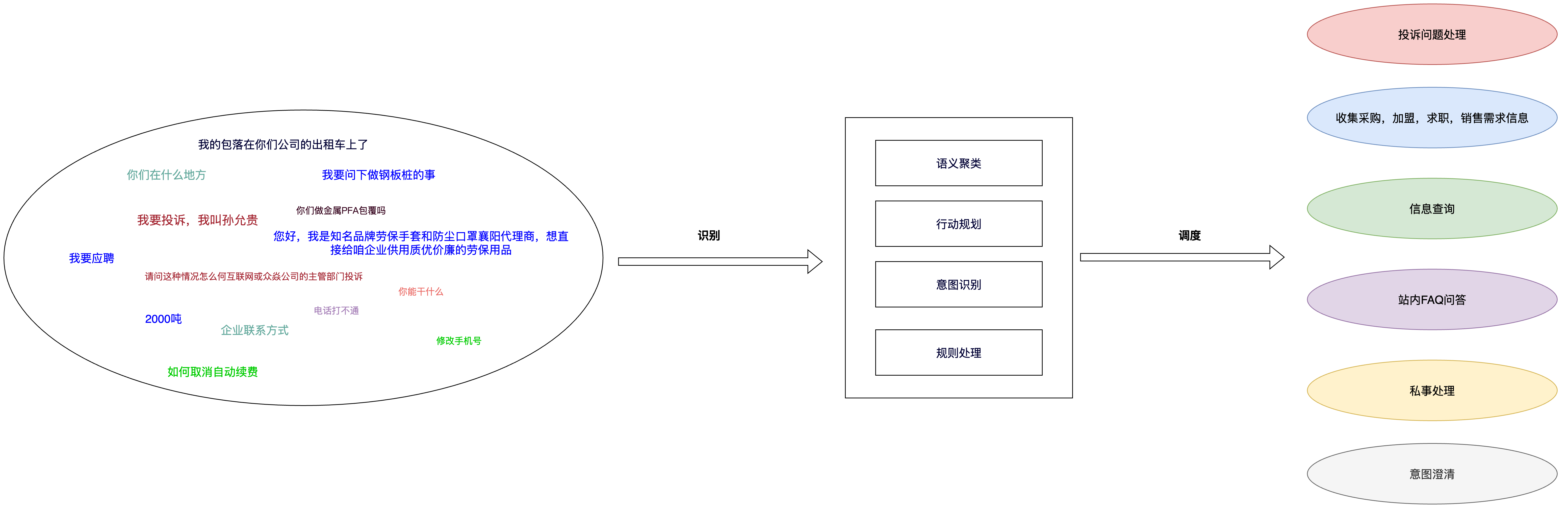
基于检索式对话和任务式对话两种形式,结合业务场景,主要划分了6大类对话链路。场景的划分是基于用户历史用户会话数据分析,然后根据相关主体,具有的能力以及数据进行链路抽象。当前爱企查拥有企业信息,站内FAQ信息,b2b行业数据以及企业主自维护信息等,根据用户的需求以及需求满足形式将链路整体分为检索式对话以及任务式对话两种形式。结合这两种对话形式以及用户的具体需求主要划分出了六条对话链路,通过语义聚类,基于大模型的行动规划,意图识别和规则处理这些手段将开放的用户问题空间映射到有限的解空间里。意图识别和行动建议是主要的对话调度手段,通过意图识别和行动建议主要确定内容回复的方向,在此基础上,再通过语义聚类和规则处理的方式实现链路内的精细化分流和控制。
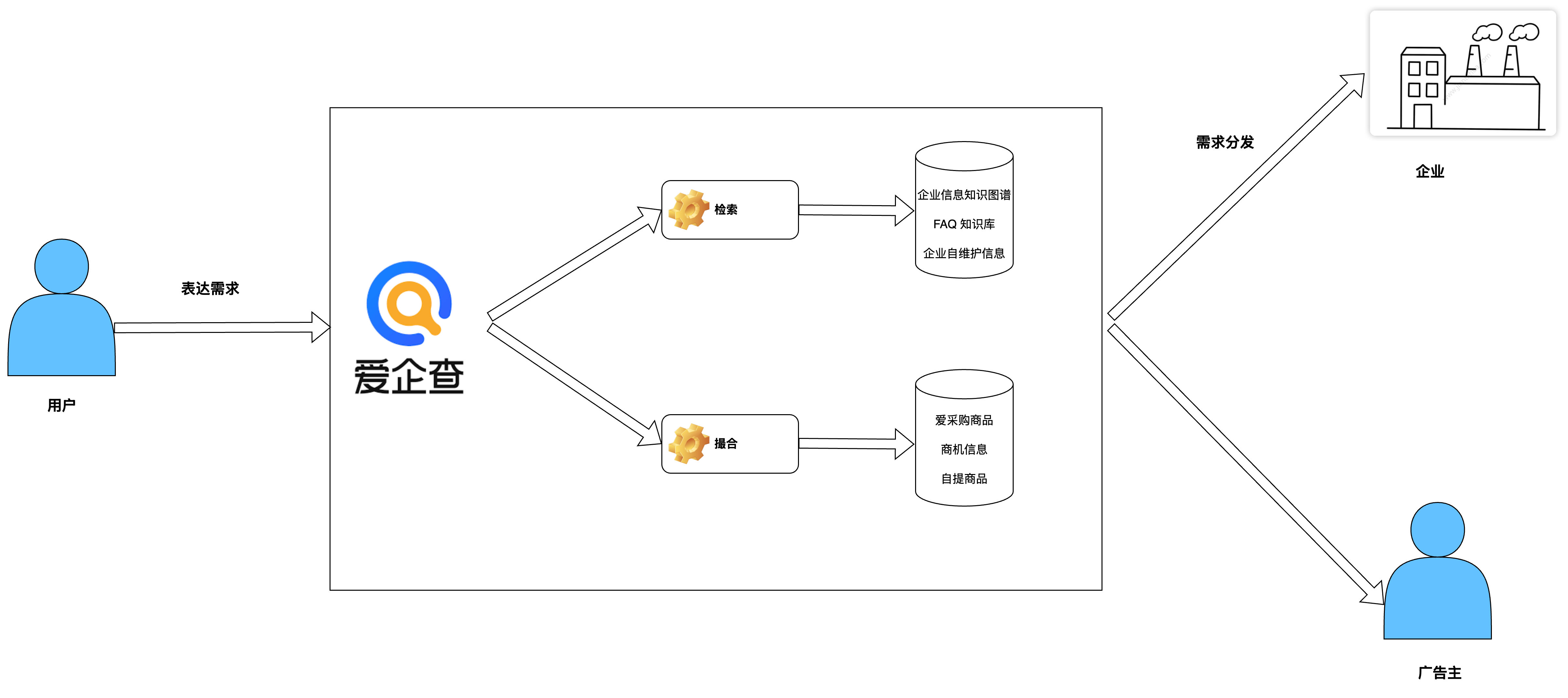
检索式对话主要依靠已有的数据和能力实现用户需求的及时满足,主要依赖企业信息知识图谱以及向量知识库。企业信息知识图谱是基于大模型和图数据库的自然语言信息检索系统,能够根据自然语言检索企业人员信息。向量知识库是基于向量数据库和大模型 Embedding 能力搭建的语义检索系统,通过向量知识库实现了站内 FAQ 的自助解决。
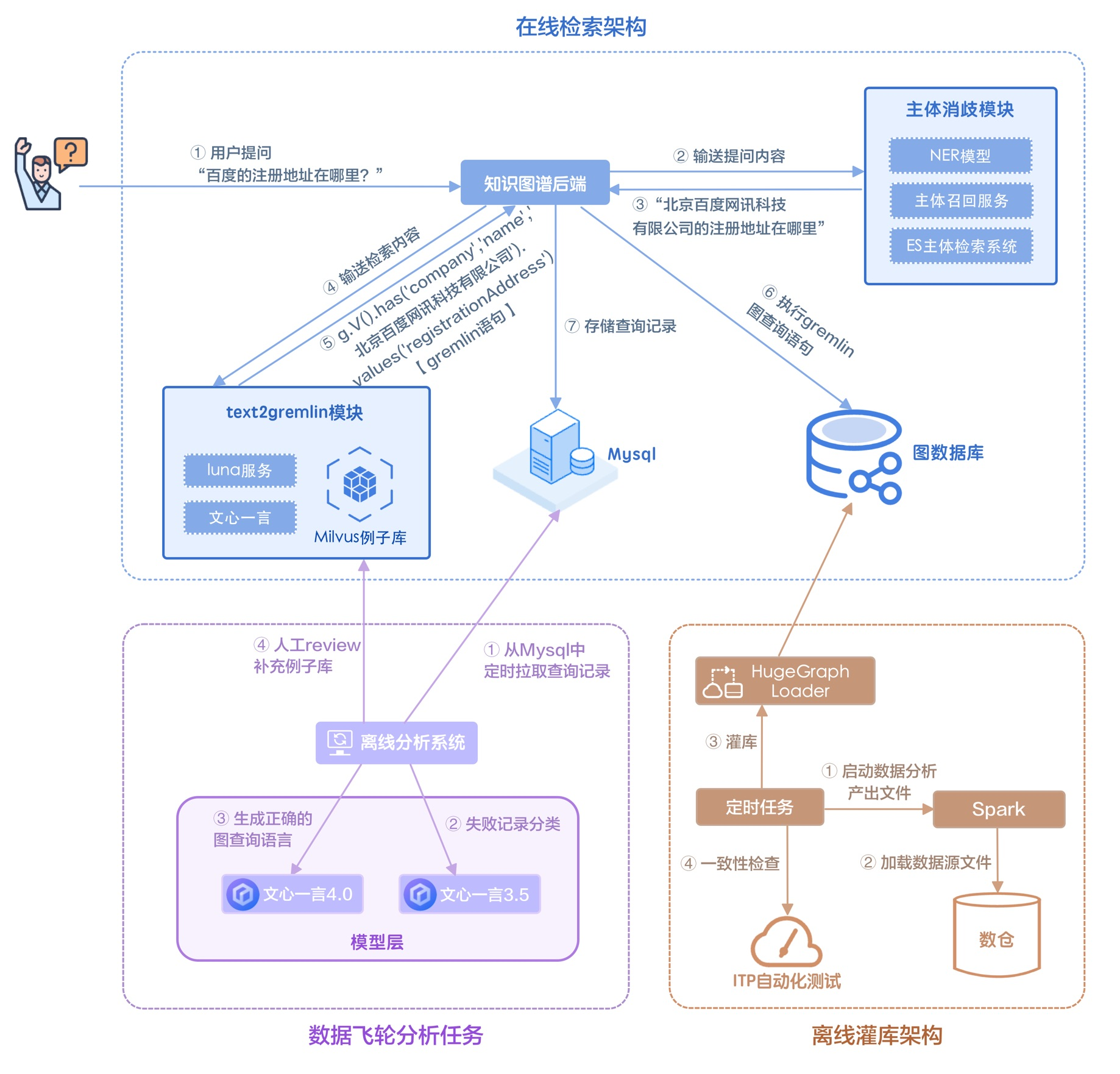
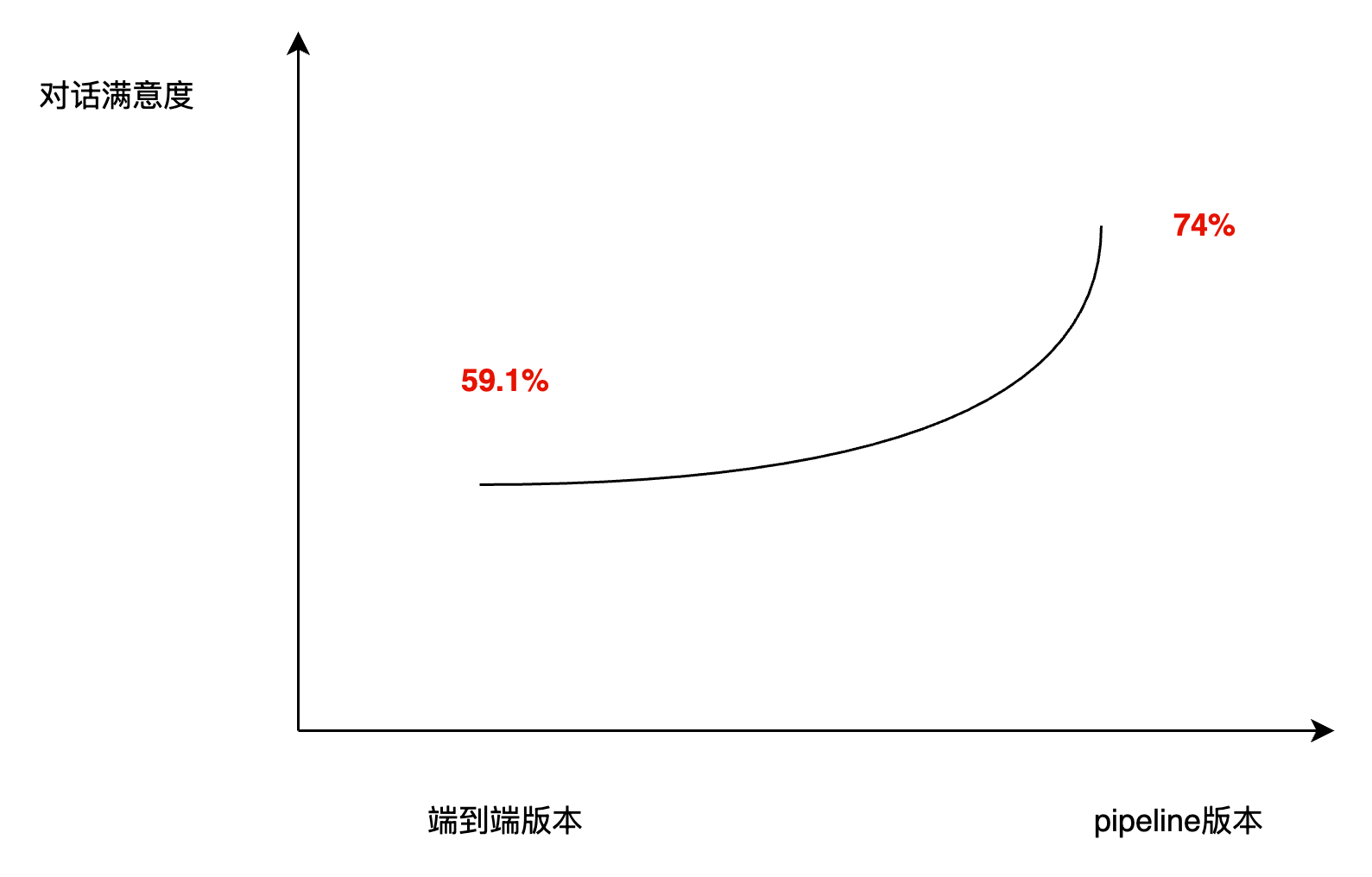
任务式对话主要针对用户需求进行信息收集和供给推荐。整个任务式对话是基于 pipeline 的方式编排的,包含意图识别,行动决策,对话状态记录等步骤。选择基于 pipeline 的形式主要是因为当前大模型能力有限且用户场景多,端到端的方案对回复内容的控制力度较弱,通过 pipeline 的方式将整个对话流程进行细分以后,能够实现对话方向和内容的精细控制。

检索式对话和任务式对话都依赖大模型生成最终回复内容。在模型选择上,我们主要考量模型的成本,生成速度以及效果等因素,针对不同的场景选择适合的模型。我们通过使用相同的评估集在多个模型上生成结果,评估模型在具体场景下的效果和生成速度。效果评估按照GSB的评估方式对结果之间进行打分,从而获得模型之间的效果对比。为了实现 case 干预以及生成速度的提升,我们针对行动规划环节进行了 SFT 训练,在效果持平的情况下通过 SFT eb-speed 模型我们实现了整体生成速度近40%的提升。
在多次迭代和优化过程中,我们遇到了系统优化评估和测试的问题。针对如此多的用户场景和回复链路,人工测试无法系统反映优化前后的整体变化,同时没有足够的人力。因此,我们主要通过采样用户线上的对话进行线下回放,针对回放生成的对话结果进行评估对比。虽然通过线上数据回放实现了线下系统的整体度量,但是回放结果的评估依然需要人力投入,同时 SFT 模型的训练数据标注也占用了大量的人力。因此,为了减少人工评估和标注的投入,针对这两个场景我们主要引入了大模型进行辅助标注和评估。
.png)
大模型技术
什么是大模型
大模型一般是指参数规模上亿的模型,参数决定了神经元之间的连接强度。单个神经元的数学公式可以表示为$h_j = f\left(\sum_i w_{ij} \cdot x_i + b_j\right) $,其中$w_{ij}$代表了第 i 个神经元到第 j 个神经元之间的权重,$ b_j$代表了第 j 个神经元的偏置(是一个常数值)。整个模型由大量的神经元构成,对应的数学表达式为$\begin{aligned} Y &= \text{LN}(X + \text{MHA}(X)) \ Z &= \text{LN}(Y + \text{FFN}(Y)) \ \text{where:} \ \text{MHA}(X) &= \text{Concat}(\text{head}_1, …, \text{head}_h)W^O \ \text{head}_i &= \text{Attention}(XW^Q_i, XW^K_i, XW^V_i) \ \text{Attention}(Q, K, V) &= \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \ \text{FFN}(x) &= \max(0, xW_1 + b_1)W_2 + b_2 \end{aligned}$。
大模型通过不断的训练调整参数,来拟合物理世界的规律,这些规律包含了语句的组成结构,事物的发展规律等等。而大模型学习到的定理,知识和规律都反映在了词元(token)的关联性上。大模型通过学习大量的数据,了解到了下雨和雨伞,积水等概念的相关性,在内容生成时,根据前序内容不断根据特定的策略从一系列相关词元中选择下一个词元,重复这个过程直至内容生成完成。每个 token 生成都会激活模型的部分参数,进行运算,这也意味着更大参数规模的模型可能会有更长的内容生成等待时间。
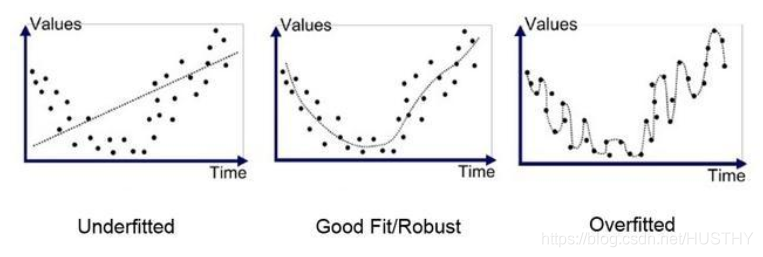
大模型幻觉
通过前面的描述我们可以知道,大模型本质上就是通过训练样本来学习相关的统计学规律,模型生成的目标是为了保证上下文的相关性和连贯性,因此可能创造性生成一些不正确或者不存在的信息。同时也可能受限于训练样本的质量和偏差,大模型也可能学习并重复这些错误。
为了减少大模型出现幻觉的概率,以及提高模型指令遵循的能力,常用的解决手段包括:
| 名称 | 成本 | 实现手段 | 适用场景 |
|---|---|---|---|
| SFT | 高 | SFT 全称是监督式微调。SFT 是指一系列的微调手段,包含PT, PFT, LoRA 等等。目前最通用的微调手段是 LoRA,该方式能够减少原模型参训练量,同时能够保证训练效果。 | 修改原模型输出内容风格需要加快生成速度运用在新的场景上相对固定的领域知识注入 |
| RAG | 中 | 通过引入外部知识库,知识库可以是静态的,如文档,也可以是动态的,如向量数据库以及知识图谱等。大模型通过 prompt 内提供的外部信息实现 In Context Learning。 | 具有时效性,频繁更新的领域知识注入对知识溯源有要求 |
| Prompt 工程 | 低 | 通过结构化的 prompt,以及 prompt 技巧(比如 COT, SOC等等)控制模型输出结果。 | N/A |
大模型生态相关的概念
RAG
RAG 的全称是 Retrieval-Augmented-Generation,即检索增强生成。即通过外部知识库检索相关信息,提高大模型生成内容的准确性和相关性。
向量 RAG
RAG 的一种实现方式。其中向量就是 n 个数字,每个数字代表了某种指标上的强弱程度,比如方位,情绪等等。不同的概念和事物之间可以通过向量去表示,通过这种数学数值的表示形式就可以通过计算的手段来衡量语义相关性。而向量 RAG 主要就通过语义相关性召回特定的物料资源。
知识图谱
可作为 RAG 的一种实现方式。知识图谱是一种用于表示和存储知识的结构化图形模型,通常由节点(企业/人员)和边(投资/任职)组成,能够帮助计算机理解和处理复杂的信息,目前主要应用于问答系统,搜索引擎和推荐系统等领域。
插件
插件的出现就是为了服务大模型的,主要包括交互增强以及知识增强两种类型。其中交互增强是指改变或优化原有模型的交互形式,比如通过绘图等形式增强文本大模型的展现效果。而知识增强是指通过 RAG 的方式注入外部知识,以提升模型回复内容的时效性以及准确性。
智能体
智能体一般具有决策以及行动能力,这意味着他比插件具有更加复杂的结构。一般来说,智能体具备多项能力,可以根据用户要求来运用这些能力,这可以是内容生成,也可以是机票预定等操作,或者是调用插件。
FAQ
研发侧是如何评估和决定使用哪个大模型的
主要根据实际效果,生成速度以及使用成本。目前实际效果和生成速度占主要衡量因素,使用成本因为目前未实际计费所以只是参考因素。实际效果包括指令遵循的能力(大模型听不听话)以及生成文本的风格。
参考资料
美团智能客服核心技术与实践 智能客服产品调研(上):客服行业分析及“在线客服机器人”产品调研分享 ChatGPT在智能客服产品中,该如何落地? – 人人都是产品经理 智能客服行业2023市场报告 智能客服行业2021市场报告